Make a Donut 🍩
Language-Guided Hierarchical EMD-Space Planning for Zero-Shot Deformable Object Manipulation
Yang You1 Bokui Shen1 Congyue Deng1 Haoran Geng2 Songlin Wei2 He Wang2 Leonidas Guibas1
1Stanford University 2Peking University

Abstract
Deformable object manipulation stands as one of the most captivating yet formidable challenges in robotics. While previous techniques have predominantly relied on learning latent dynamics through demonstrations, typically represented as either particles or images, there exists a pertinent limitation: acquiring suitable demonstrations, especially for long-horizon tasks, can be elusive. Moreover, basing learning entirely on demonstrations can hamper the model’s ability to generalize beyond the demonstrated tasks. In this work, we introduce a demonstration-free hierarchical planning approach capable of tackling intricate long-horizon tasks without necessitating any training. We employ large language models (LLMs) to articulate a high-level, stage-by-stage plan corresponding to a specified task. For every individual stage, the LLM provides both the tool’s name and the Python code to craft intermediate subgoal point clouds. With the tool and subgoal for a particular stage at our disposal, we present a granular closedloop model predictive control strategy. This leverages Differentiable Physics with Point-to-Point correspondence (DiffPhysics-P2P) loss in the earth mover distance (EMD) space, applied iteratively. Experimental findings affirm that our technique surpasses multiple benchmarks in dough manipulation, spanning both short and long horizons. Remarkably, our model demonstrates robust generalization capabilities to novel and previously unencountered complex tasks without any preliminary demonstrations. We further substantiate our approach with experimental trials on real-world robotic platforms.
Method Overview
Our method adopts a hierarchical planning approach combining both language models and low-level particle space controls. At the top level, LLMs are employed to break down a complex task into substages, and output both the code to generate subgoal states and the tool name for each. At the bottom level, given the current tool and subgoal, our technique iteratively identifies the next reachable target based on the present state and subgoal with a planning algorithm in the EMD space.
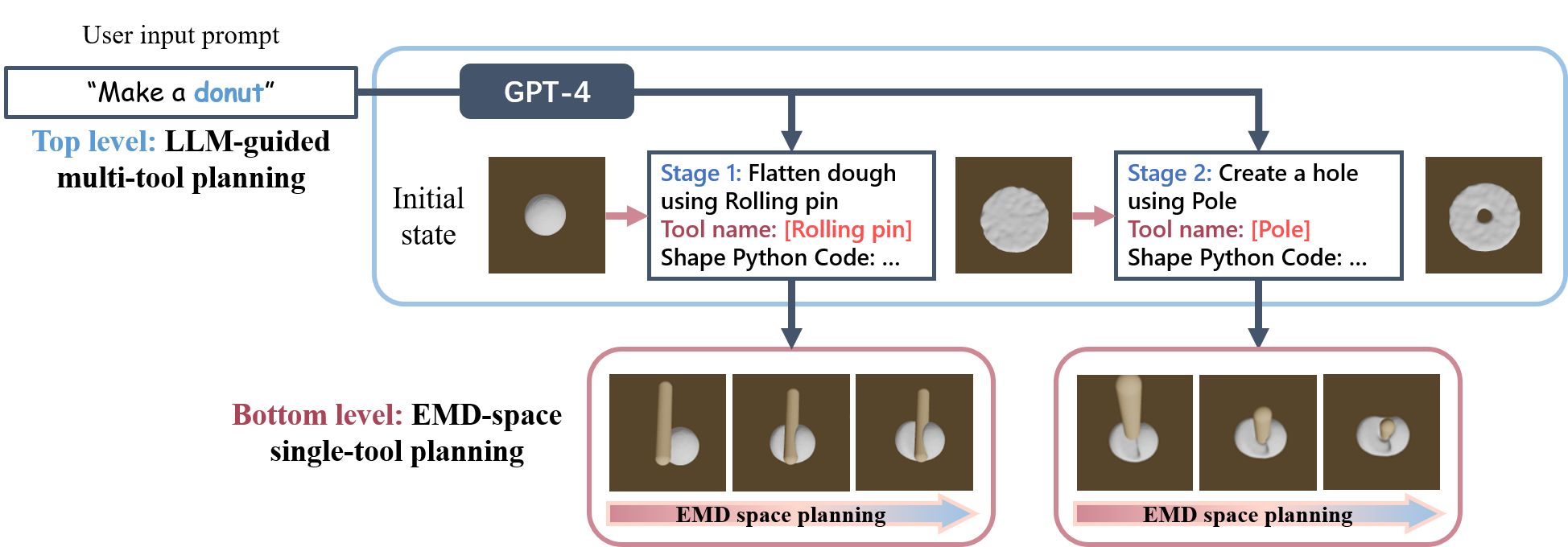
Two-Level Planning
Top level: LLM-guided multi-tool selection
To guide this process, we devised a prompt template that imparts to the LLM foundational information about available tools and their potential interactions with the dough. We ask the LLM to output the following items for each stage during planning:
Additionally, we introduce two guidelines: volumn preserving and chain of reasoning, which improves the feasibility and stability of the generated targets.

To try the prompts yourself:
- First of all, copy this template prompt into GPT-4: Template prompt
- Next, append your customized prompt specifying the goal as well as the initial dough state. Prompts for the examples in the paper are: Donut Baguette Pancakes
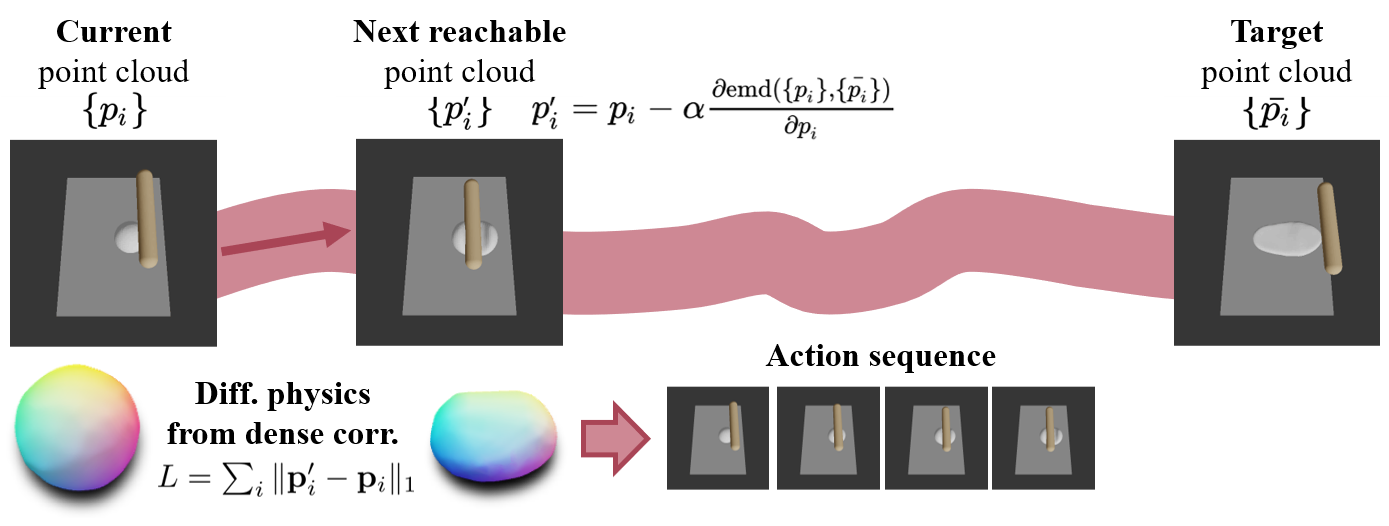
Bottom level: single-tool EMD-space planning
We find the next reachable target by running small steps within the EMD space. The induced point-to-point correspondence can provide better gradients when optimizing actions through differential physics.
Results
Simulated Experiments
"Make a Donut"
Stage 1

Stage 2

Stage 1

Stage 2

Stage 1

Stage 2

Stage 1

Stage 2

"Make a Baguette"
Stage 1

Stage 2

Stage 1

Stage 2

Stage 1

Stage 2

Stage 1

Stage 2

"Make two Pancakes"
Stage 1

Stage 2

Stage 3

Stage 1

Stage 2

Stage 3

Stage 1

Stage 2
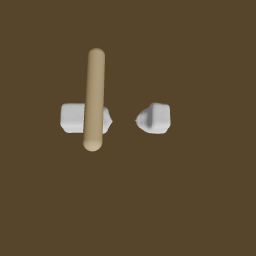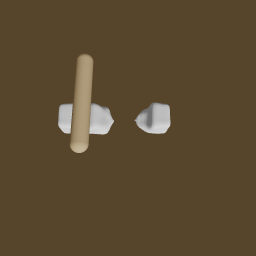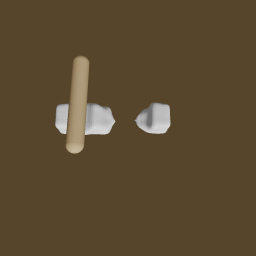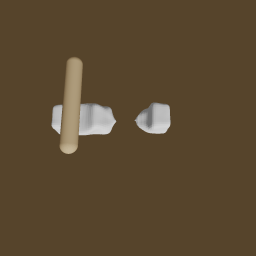
Stage 3

Stage 1

Stage 2

Stage 3

Real-Robot Experiments
BibTeX
@article{you2023make,
title={Make a Donut: Language-Guided Hierarchical EMD-Space Planning for Zero-shot Deformable Object Manipulation},
author={You, Yang and Shen, Bokui and Deng, Congyue and Geng, Haoran and Wang, He and Guibas, Leonidas},
journal={arXiv preprint arXiv:2311.02787},
year={2023}
}