

Reverse engineering 3D computer-aided design (CAD) models from images is an important task for many downstream applications including interactive editing, manufacturing, architecture, robotics, etc. The difficulty of the task lies in vast representational disparities between the CAD output and the image input. CAD models are precise, programmatic constructs that involves sequential operations combining discrete command structure with continuous attributes -- making it challenging to learn and optimize in an end-to-end fashion. Concurrently, input images introduce inherent challenges such as photometric variability and sensor noise, complicating the reverse engineering process. In this work, we introduce a novel approach that conditionally factorizes the task into two sub-problems. First, we leverage vision-language foundation models (VLMs), a finetuned Llama 3.2, to predict the global discrete base structure with semantic information. Second, we propose TrAssembler that conditioned on the discrete structure with semantics predicts the continuous attribute values. To support the training of our TrAssembler, we further constructed an annotated CAD dataset of common objects from ShapeNet. Putting all together, our approach and data demonstrate significant first steps towards CAD-ifying images in the wild.
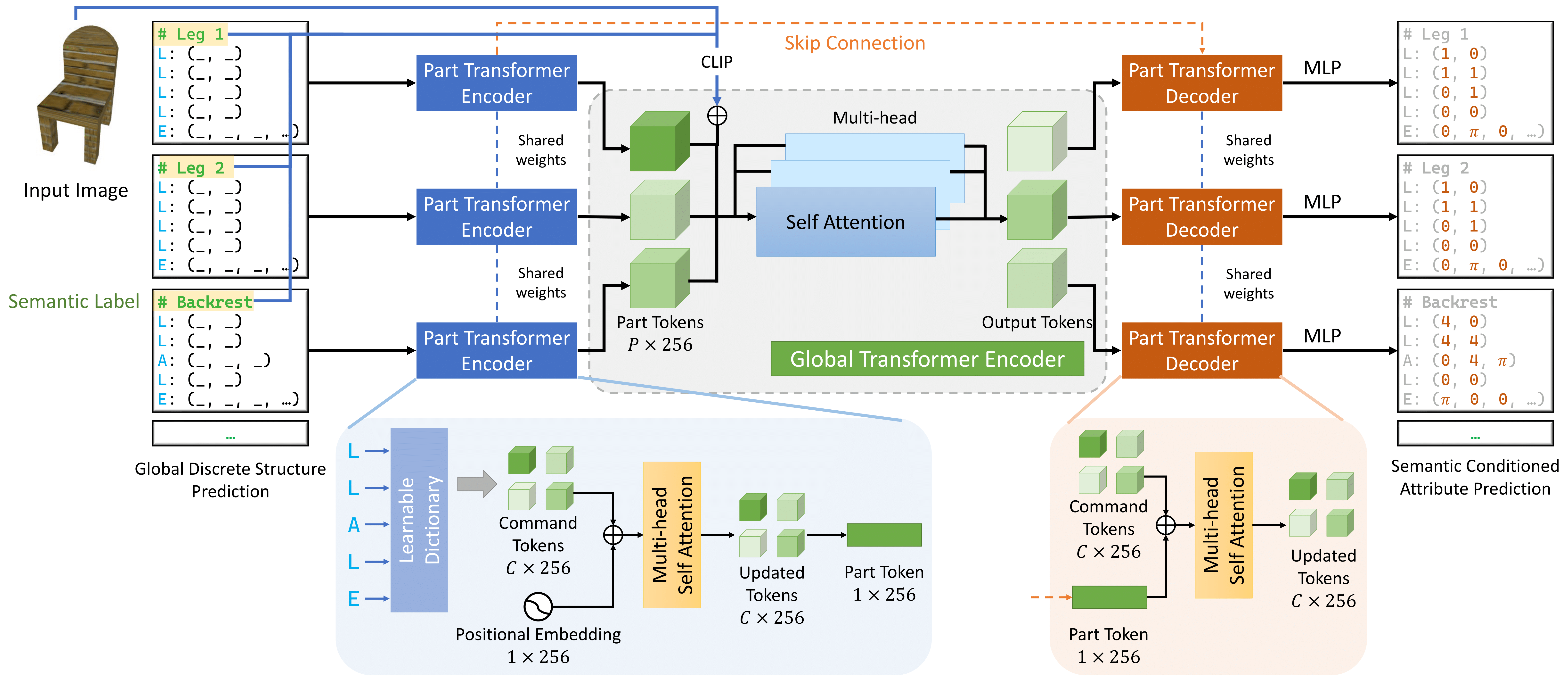
The task of reverse engineering a 3D model from input images is a challenging task in the computer graphics and vision literature due to the discrete-continuous nature of the problem, requiring the learning of the combinatorial space of shape and program structure and their corresponding continuous attributes. Our approach tackles the challenging image-to-CAD problem for common objects through conditionally factorizing the task into two sub-problems. First, we leverage on the capabilities of finetuned large foundation models (i.e., Llama 3.2) to predict the global discrete base structure of the shape from a single input image. This discrete problem includes inferring the semantics parts that are present in the image as well as providing the CAD structure, i.e. command types, of each underlying part. We then propose a novel transformer-based model that conditioned on this semantic-informed, discrete base structure predicts the continuous attributes for the sequence of CAD commands for each semantic part.









