
PACE is a large-scale object pose dataset with diverse objects, complex scenes, and various types of occlusions, reflecting real-world challenges.
We introduce PACE (Pose Annotations in Cluttered Environments), a large-scale benchmark designed to advance the development and evaluation of pose estimation methods in cluttered scenarios. PACE provides a large-scale real-world benchmark for both instance-level and category-level settings. The benchmark consists of 55K frames with 258K annotations across 300 videos, covering 238 objects from 43 categories and featuring a mix of rigid and articulated items in cluttered scenes. To annotate the real-world data efficiently, we develop an innovative annotation system with a calibrated 3-camera setup. Additionally, we offer PACESim, which contains 100K photo-realistic simulated frames with 2.4M annotations across 931 objects. We test state-of-the-art algorithms in PACE along two tracks: pose estimation, and object pose tracking, revealing the benchmark’s challenges and research opportunities.
PACE is a large-scale object pose dataset with diverse objects, complex scenes, and various types of occlusions, reflecting real-world challenges.
The PACE dataset provides comprehensive annotations for each frame, including RGB images, depth maps, instance masks, and Normalized Object Coordinate Space (NOCS) maps. These annotations are crucial for training and evaluating pose estimation models. The slider below showcases the various types of annotations available in our dataset.

RGB

Rendered Object

Object Pose

Depth

NOCS Map

Instance Mask

RGB

Rendered Object
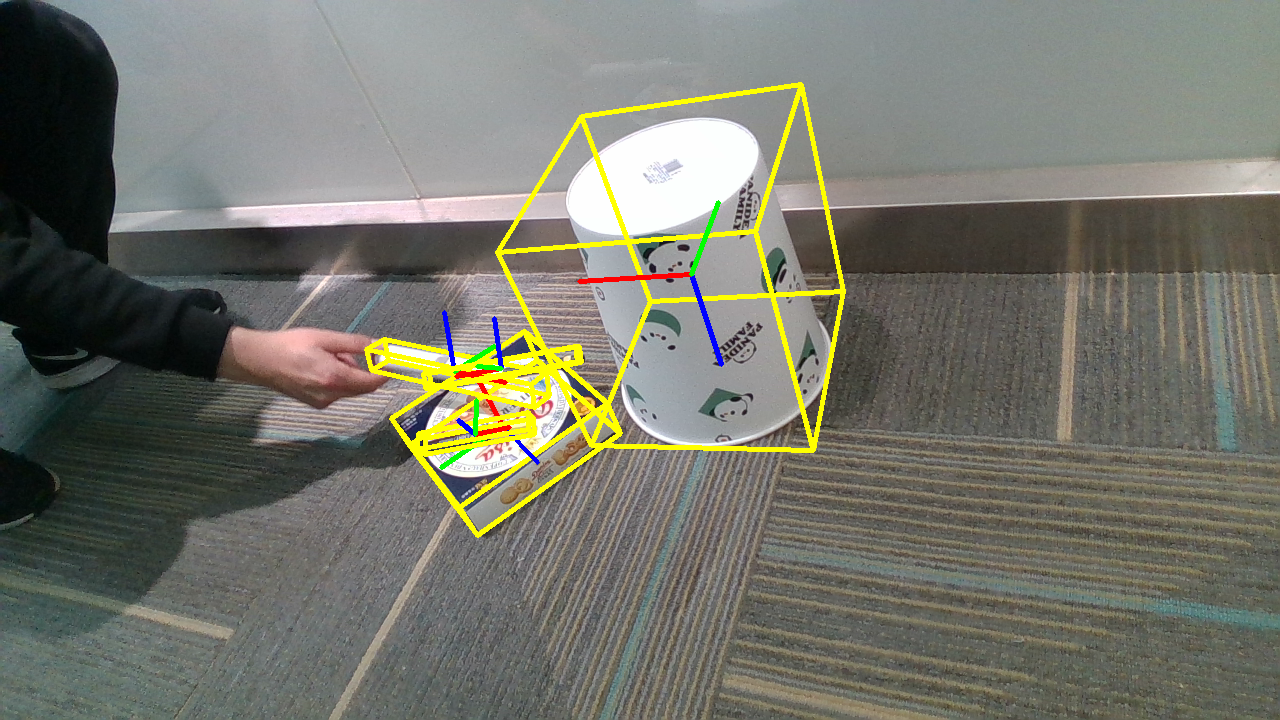
Object Pose

Depth
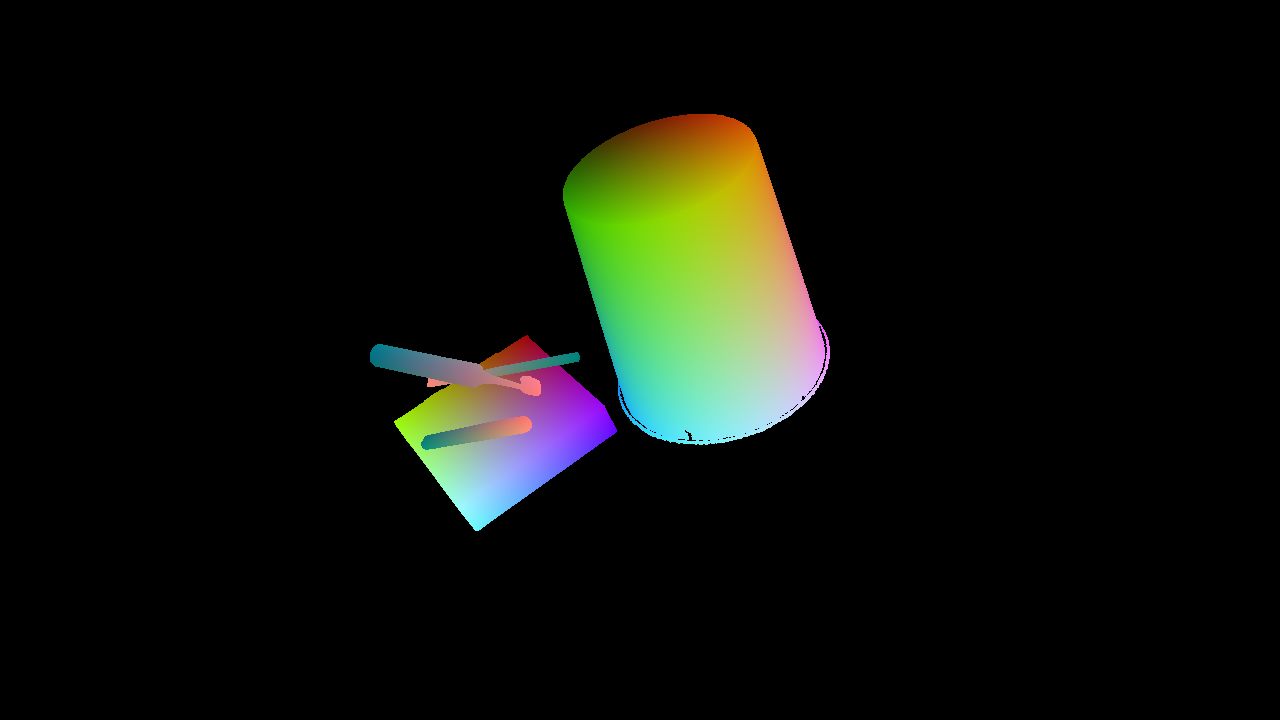
NOCS Map

Instance Mask

RGB

Rendered Object

Object Pose

Depth
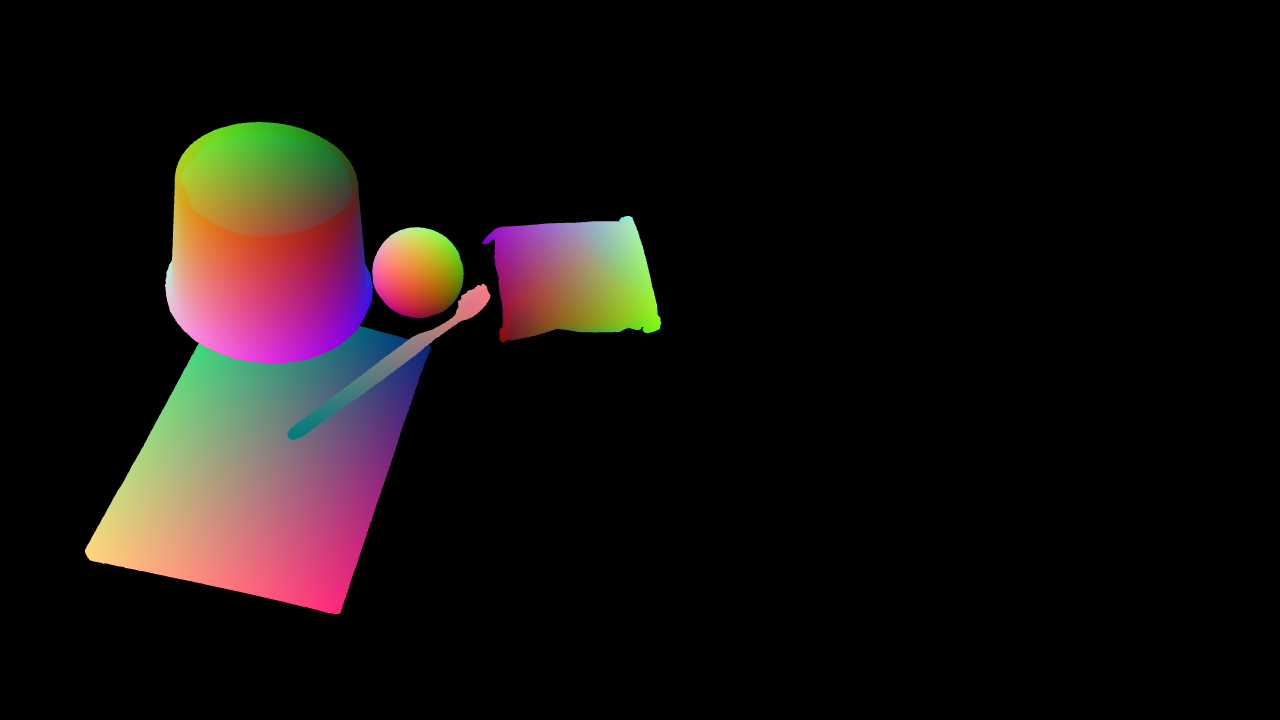
NOCS Map

Instance Mask

RGB
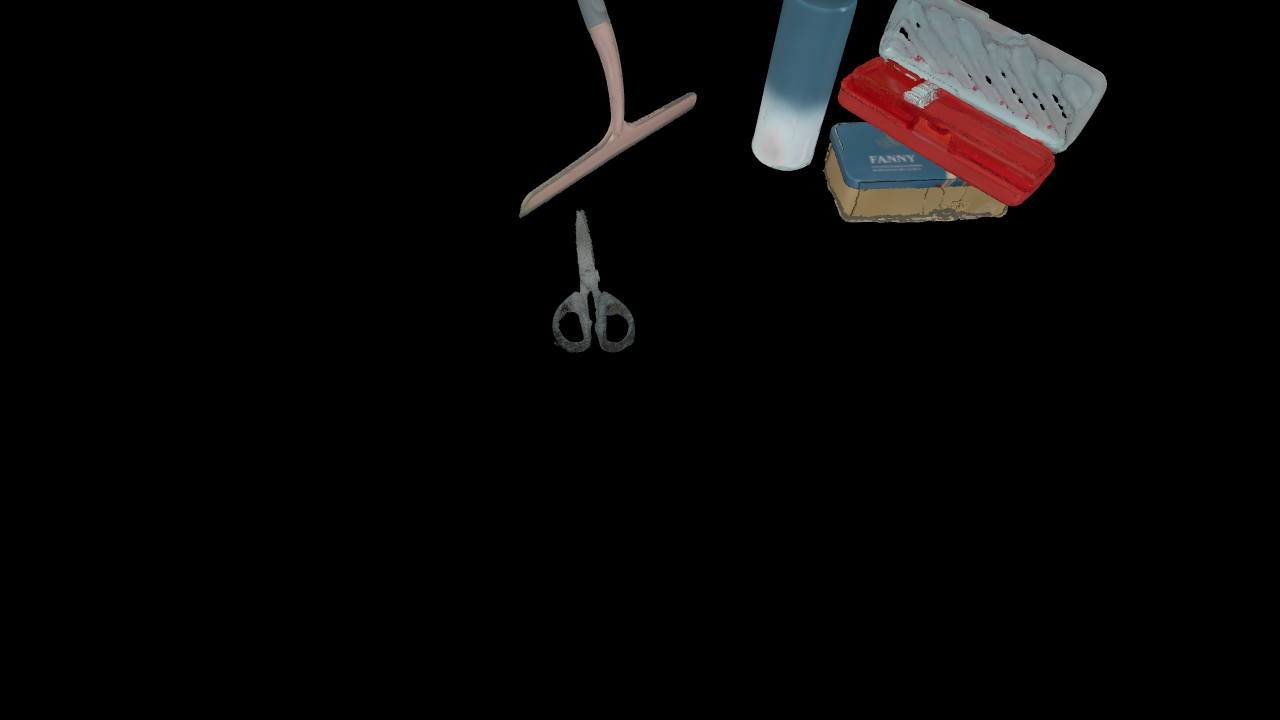
Rendered Object
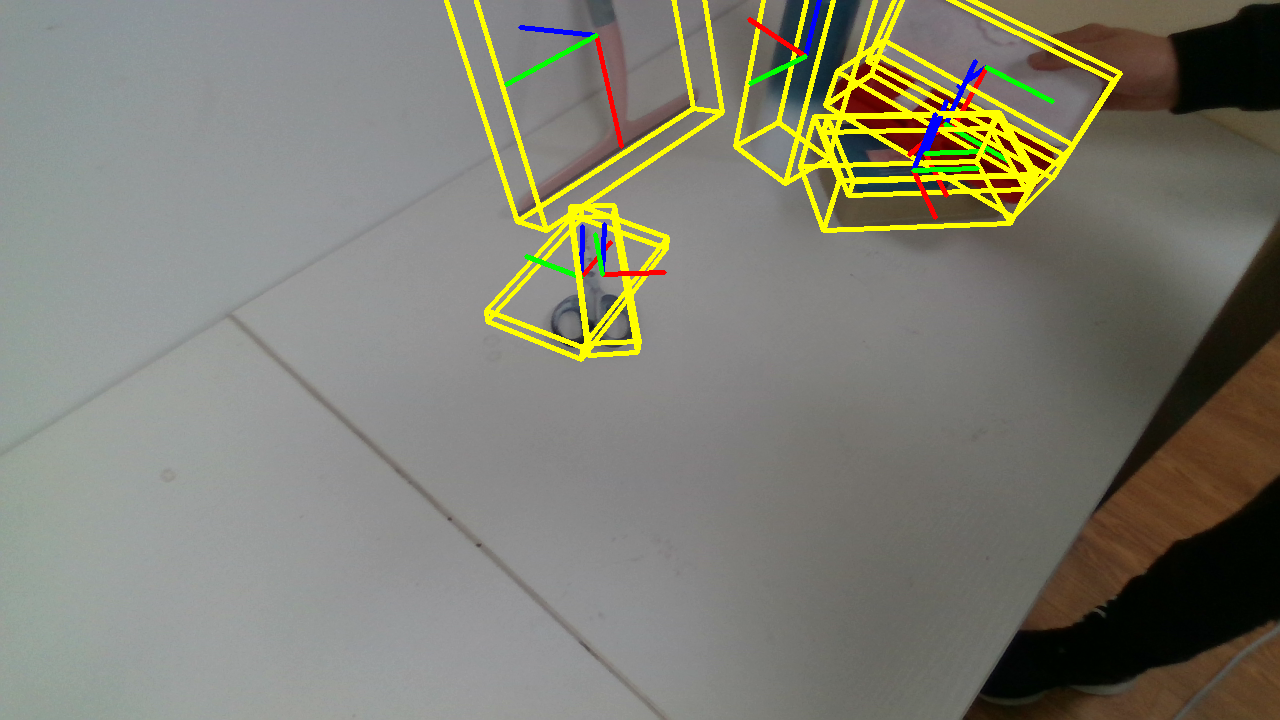
Object Pose

Depth

NOCS Map

Instance Mask

RGB

Rendered Object
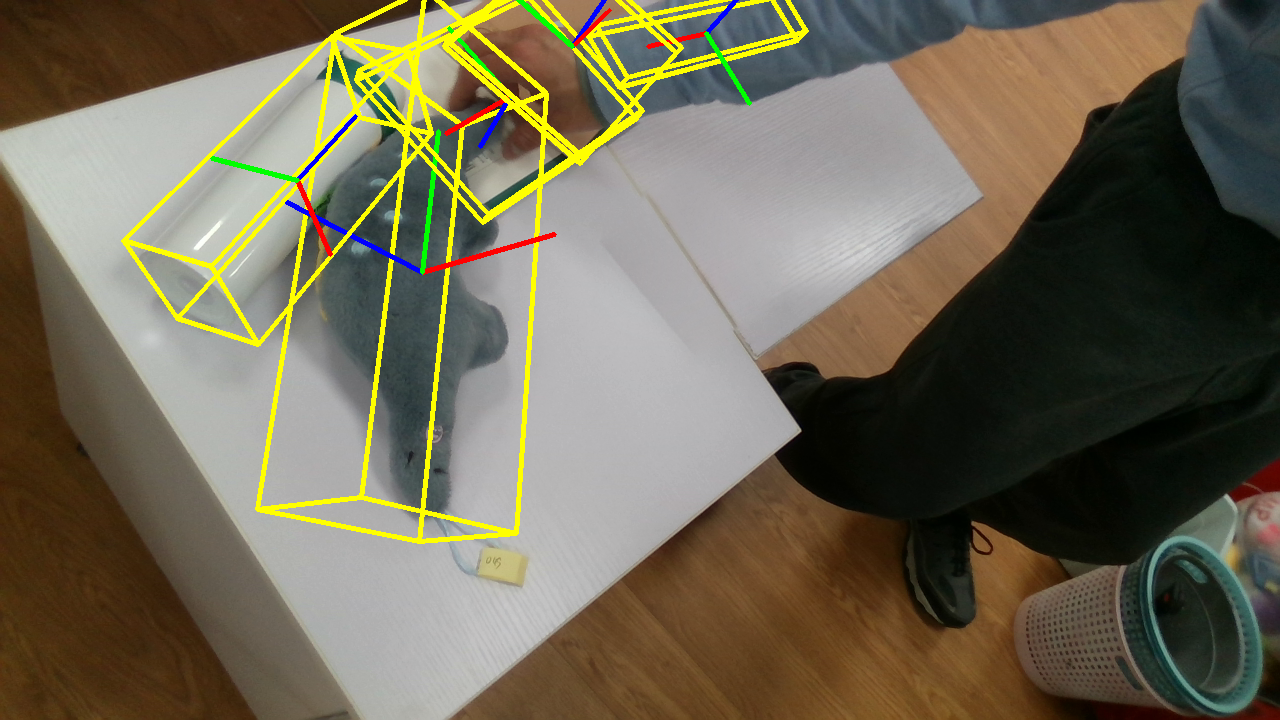
Object Pose

Depth

NOCS Map

Instance Mask
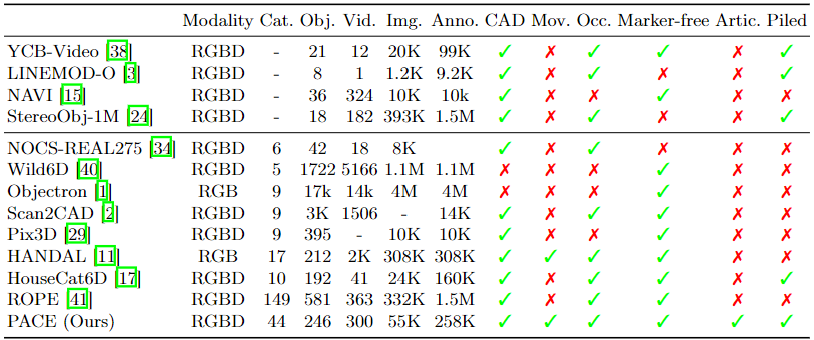
The PACE dataset is compared with other existing datasets in terms of modality, number of categories, objects, videos, images, and annotations. The table highlights the scale and diversity of PACE, which includes a large number of objects and annotations in cluttered environments, making it a challenging benchmark for pose estimation.
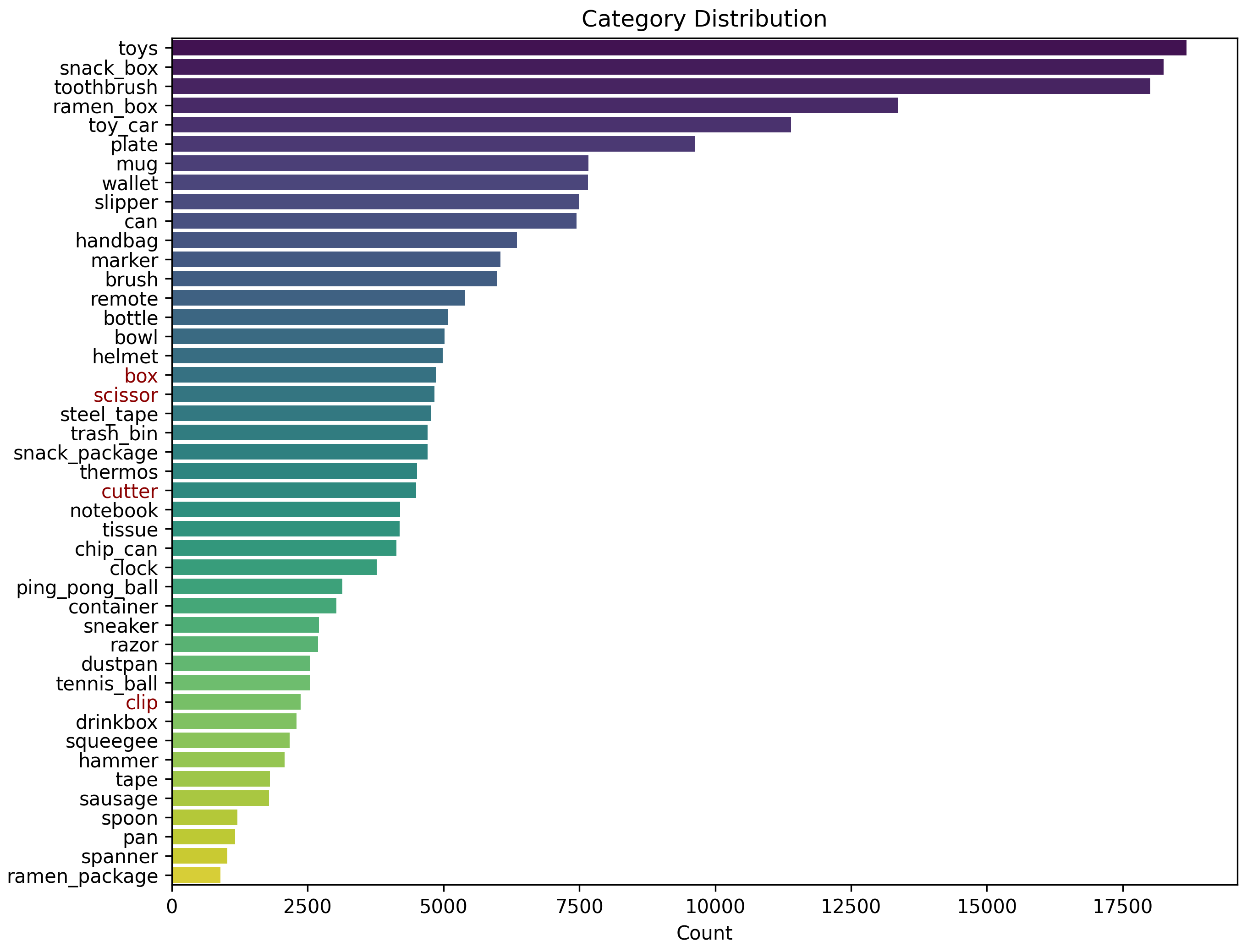
The distribution of data in the PACE dataset is analyzed across several dimensions. The graphs below show the distribution of pose annotations, object instances, object sizes, azimuth and elevation, and occlusion. This analysis provides insights into the diversity and complexity of the dataset.
Pose Annotation Distrubtion
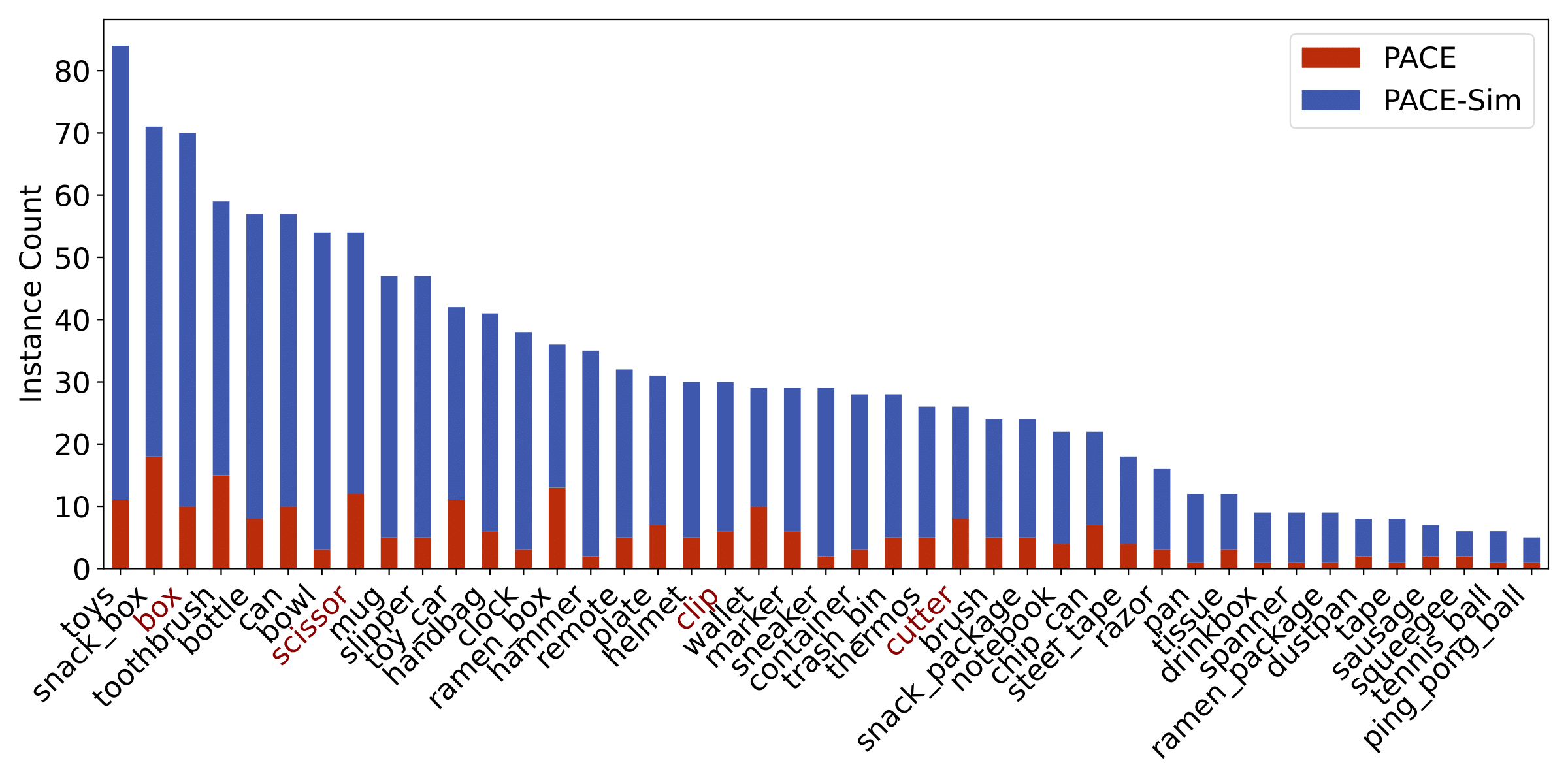
Object Instance Distrubtion
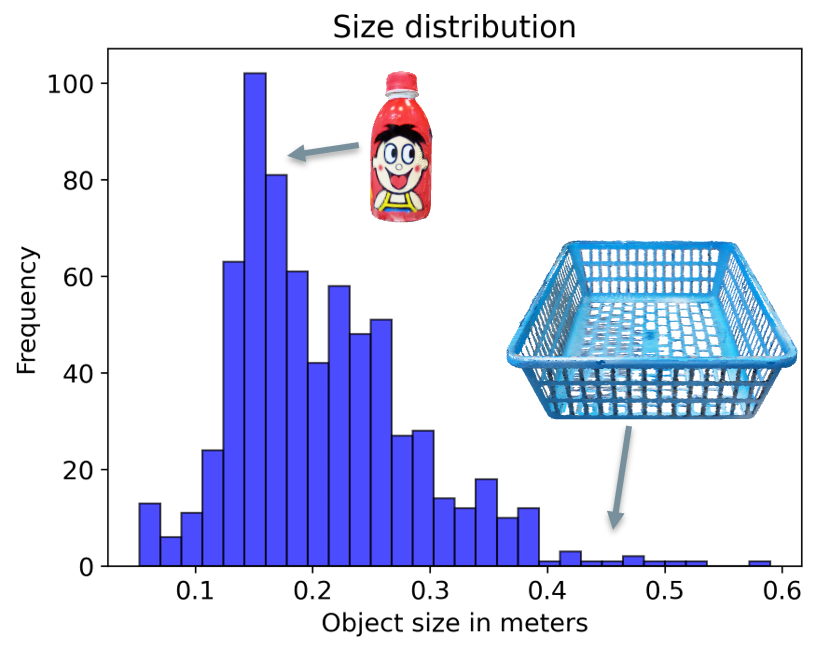
Object Size Distrubtion
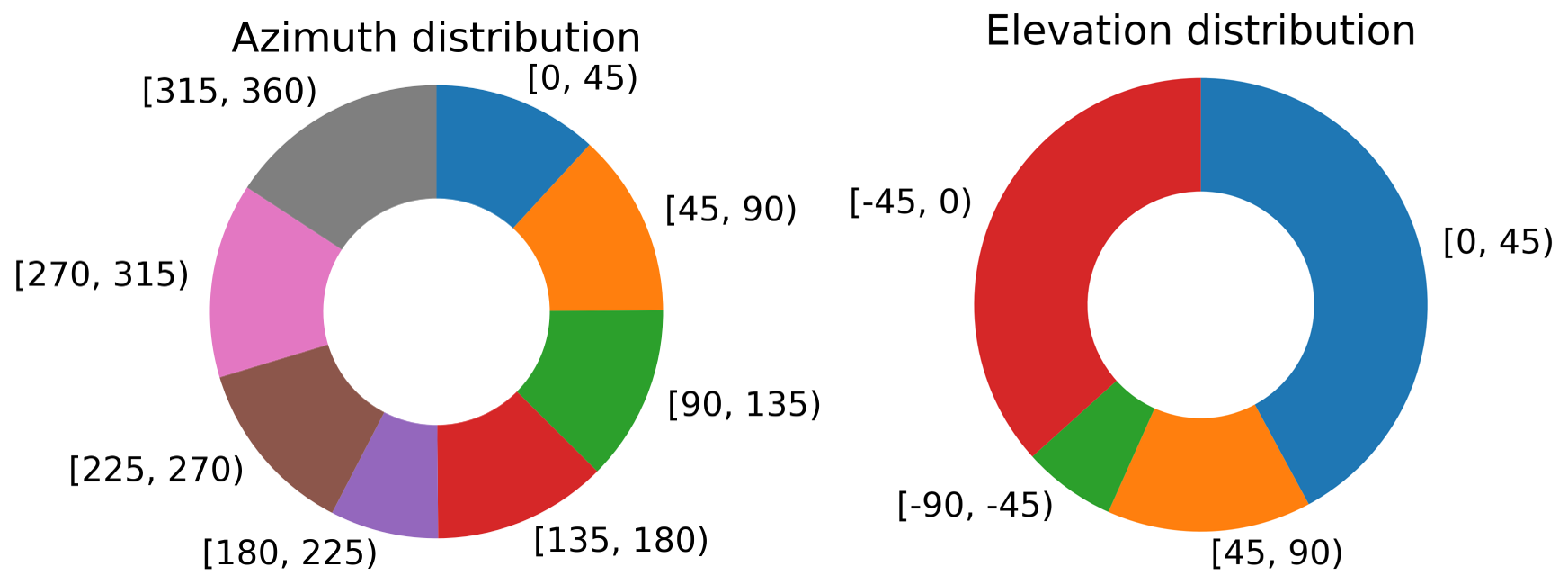
Azimuth and Elevation Distrubtion
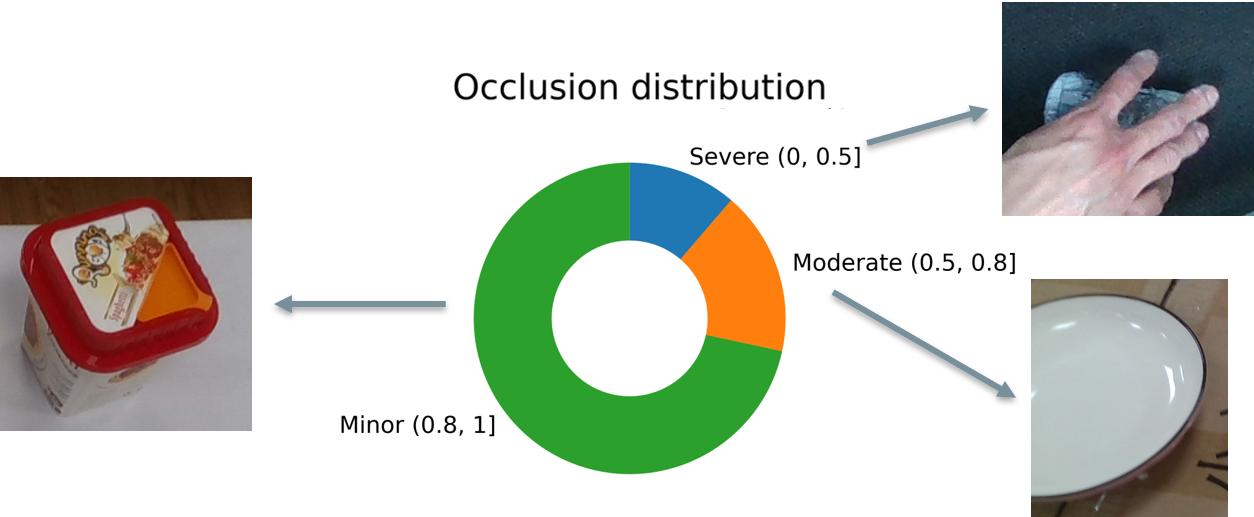
Occlusion Distrubtion
We evaluate state-of-the-art algorithms on the PACE benchmark for both pose estimation and object pose tracking. The results reveal the challenges posed by our dataset and highlight opportunities for future research. The benchmarks are divided into instance-level and category-level pose estimation, as well as model-free and model-based pose tracking.
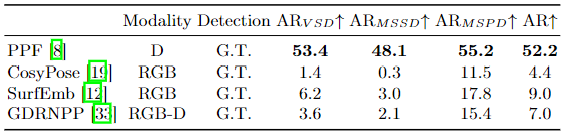
Instance-level Pose Estimation
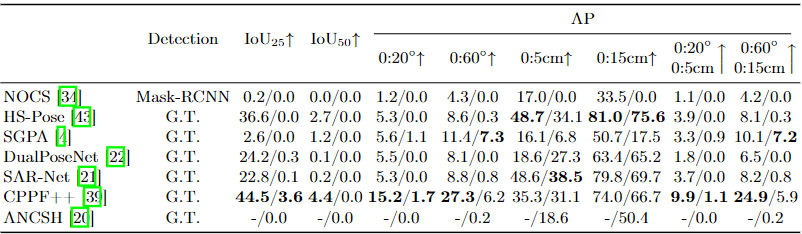
Category-level Pose Estimation

Model-free Pose Tracking

Model-based Pose Tracking
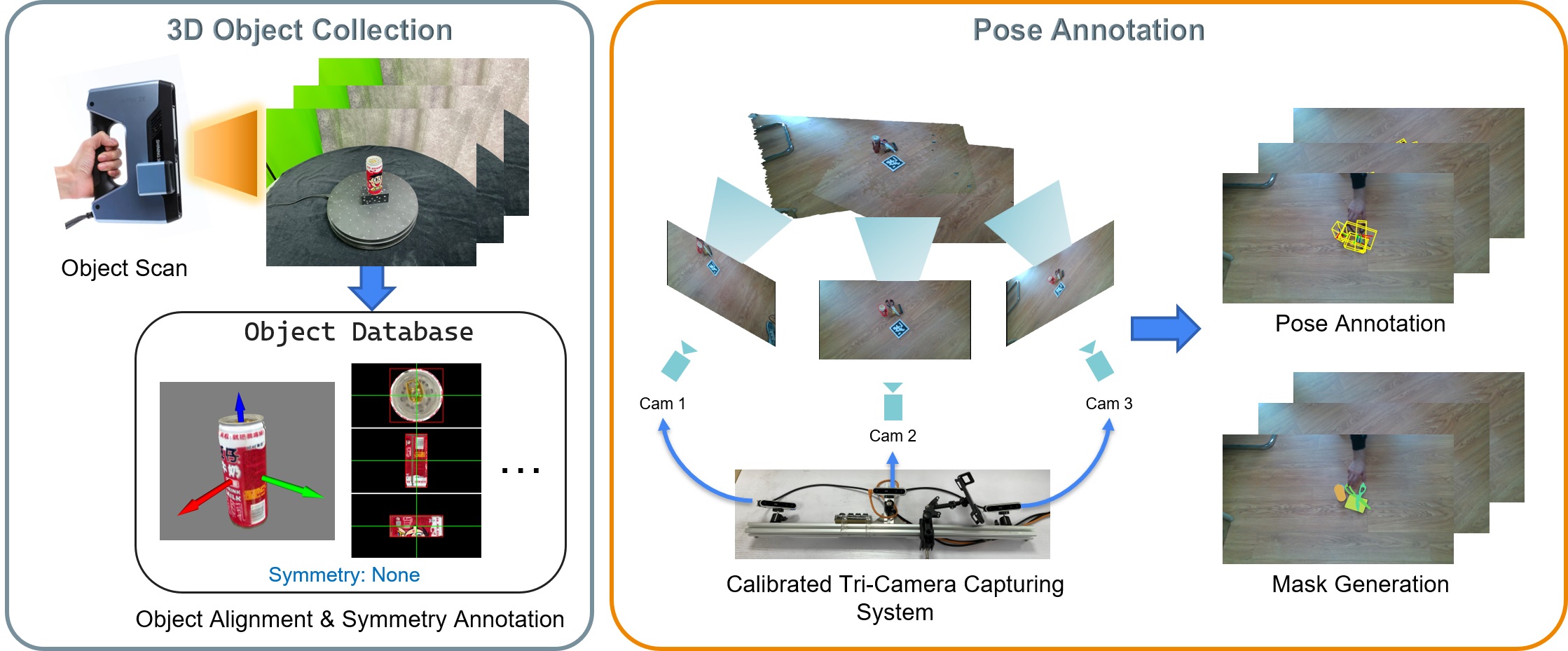
To efficiently annotate real-world data, we developed an innovative annotation system with a calibrated 3-camera setup. This pipeline enables the acquisition of high-quality 3D scans of objects and their corresponding poses in cluttered scenes. The image below provides an overview of our data collection and annotation pipeline.
@misc{you2023pace,
title={PACE: Pose Annotations in Cluttered Environments},
author={You, Yang and Xiong, Kai and Yang, Zhening and Huang, Zhengxiang and Zhou, Junwei and Shi, Ruoxi and Fang, Zhou and Harley, Adam W. and Guibas, Leonidas and Lu, Cewu},
booktitle={European Conference on Computer Vision},
year={2024},
organization={Springer}
}