
Publications and Preprints
You can also find my articles on my Google Scholar profile.
 | DOT-Sim: Differentiable Optical Tactile Simulation with Precise Real-to-Sim Physical CalibrationYang You, Won Kyung Do, Aiden Swann, Rika Antonova, Monroe Kennedy, Leonidas GuibasICRA, 2026 arxiv / Project Page /DOT-Sim is a differentiable optical tactile simulator that models soft sensors as elastic materials via the Material Point Method (MPM), enabling rapid real-to-sim calibration within minutes and supporting large, non-linear deformations. It simulates optical responses by learning a residual image relative to the real-world idle state, and demonstrates strong zero-shot sim-to-real performance on a DenseTact sensor across object classification, embedded tumor detection, and precise trajectory following. |
 | Img2CAD: Reverse Engineering 3D CAD Models from Images through VLM-Assisted Conditional FactorizationYang You, Mikaela Angelina Uy, Jiaqi Han, Rahul Thomas, Haotong Zhang, Yi Du, Hansheng Chen, Francis Engelmann, Suya You, Leonidas GuibasSIGGRAPH Asia, 2025 arxiv / code / Project Page /Img2CAD introduces a novel approach for reconstructing 3D CAD models from single-view images. Leveraging large vision-language models (VLMs) like GPT-4V for semantic guidance, and TrAssembler, a transformer-based network, for continuous attribute prediction, our method achieves accurate and editable CAD outputs from common image inputs. We also provide a newly curated dataset, CAD-ified from ShapeNet, covering diverse everyday objects. |
 | Robot Learning from Any ImagesSiheng Zhao, Jiageng Mao, Wei Chow, Zeyu Shangguan, Tianheng Shi, Rong Xue, Yuxi Zheng, Yijia Weng, Yang You, Daniel Seita, Leonidas Guibas, Sergey Zakharov, Vitor Guizilini, Yue WangCoRL, 2025 arxiv / code / Project Page /RoLA is a framework that transforms any in-the-wild image into an interactive, physics-enabled robotic environment. It operates directly on a single image without requiring additional hardware or digital assets. RoLA democratizes robotic data generation by producing massive visuomotor robotic demonstrations within minutes from a wide range of image sources. |
 | ARCH: Hierarchical Hybrid Learning for Long-Horizon Contact-Rich Robotic AssemblyJiankai Sun, Aidan Curtis, Yang You, Yan Xu, Michael Koehle, Qianzhong Chen, Suning Huang, Leonidas Guibas, Sachin Chitta, Mac Schwager, Hui LiCoRL, 2025 arxiv / Project Page /ARCH proposes a hierarchical modular approach for long-horizon, high-precision robotic assembly in contact-rich settings. It employs a hierarchical planning framework, including a low-level primitive library of parameterized skills and a high-level policy learned via IL. ARCH generalizes well to unseen objects and outperforms baseline methods in terms of success rate and data efficiency. |
| | AllTracker: Efficient Dense Point Tracking at High ResolutionAdam W. Harley, Yang You, Xinglong Sun, Yang Zheng, Nikhil Raghuraman, Yunqi Gu, Sheldon Liang, Wen-Hsuan Chu, Achal Dave, Pavel Tokmakov, Suya You, Rares Ambrus, Katerina Fragkiadaki, Leonidas J. GuibasICCV, 2025 arxiv / code / Project Page /We introduce AllTracker: a model that estimates long-range point tracks by computing flow fields between a query frame and every other frame of a video. Unlike existing methods, our approach delivers high-resolution, dense correspondence fields that can track hundreds of frames at once. The model uses an efficient architecture with iterative inference on low-resolution grids, combining 2D convolutions for spatial propagation and pixel-aligned attention for temporal propagation. With only 16 million parameters, it achieves state-of-the-art point tracking accuracy at high resolution (768x1024 pixels) and can be trained on diverse datasets for optimal performance. |
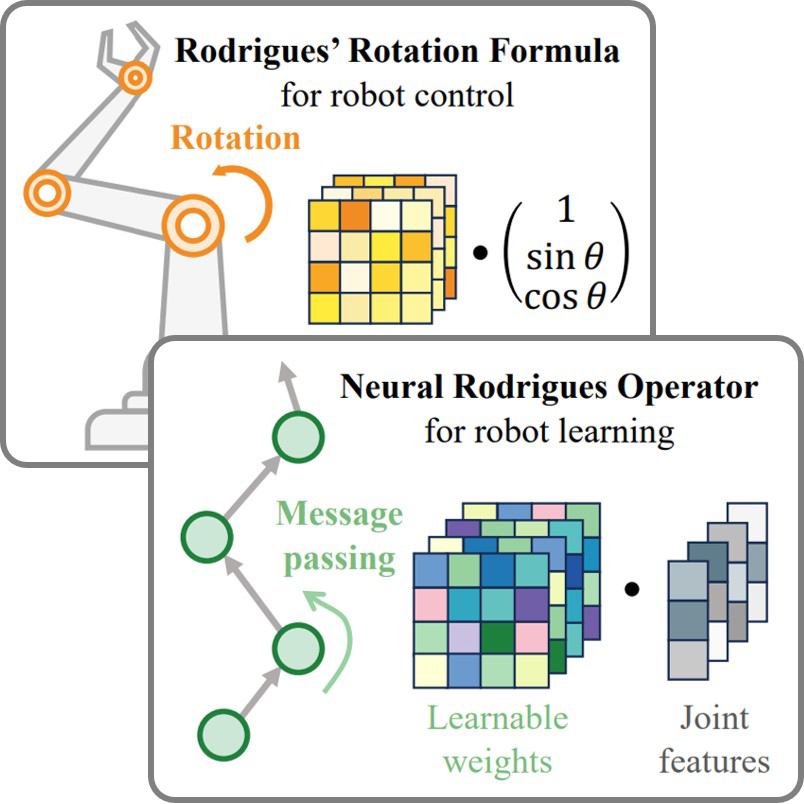 | Rodrigues Network for Learning Robot ActionsJialiang Zhang*, Haoran Geng*, Yang You*, Congyue Deng, Pieter Abbeel, Jitendra Malik, Leonidas GuibasICLR, 2026 arxiv / Project Page /This work introduces the Neural Rodrigues Operator, a learnable generalization of the classical Rodrigues’ rotation formula, to embed kinematic inductive bias directly into neural networks. Built upon this operator, the proposed Rodrigues Network (RodriNet) effectively models articulated actions and significantly improves performance across tasks like forward kinematics prediction, imitation learning for robot manipulation, and 3D hand pose estimation from images. |
 | Multiview Equivariance Improves 3D Correspondence Understanding with Minimal Feature FinetuningYang You, Yixin Li, Congyue Deng, Yue Wang, Leonidas GuibasICLR, 2025 arxiv / code / Project Page /This work evaluates and improves the 3D awareness of Vision Transformer (ViT)-based models, showing that enhancing 3D equivariance in their semantic embeddings leads to better performance in tasks like pose estimation and tracking. The authors propose a simple finetuning strategy based on 3D correspondences, demonstrating substantial improvements with minimal finetuning on a single object. |
 | ProvNeRF: Modeling per Point Provenance in NeRFs as a Stochastic ProcessGeorge Kiyohiro Nakayama, Mikaela Angelina Uy, Yang You, Ke Li, Leonidas GuibasNeurIPS, 2024 arxiv / Project Page /Neural radiance fields (NeRFs) excel at 3D scene reconstruction but struggle with sparse, unconstrained camera views. ProvNeRF addresses this by modeling per-point provenance as a stochastic process, enabling improved uncertainty estimation, criteria-based view optimization, and enhanced novel view synthesis. Our method, compatible with any pre-trained NeRF, extends IMLE for stochastic processes, leveraging training camera poses to enrich the 3D point information. |
 | CPPF++: Uncertainty-Aware Sim2Real Object Pose Estimation by Vote AggregationYang You, Wenhao He, Jin Liu, Hongkai Xiong, Weiming Wang, Cewu LuTPAMI, 2024 arxiv / code / Project Page /Object pose estimation is crucial in 3D vision, but real-world data collection is costly. This paper presents CPPF++, a new sim-to-real pose estimation method using only 3D CAD models. CPPF++ enhances the point-pair voting scheme with probabilistic modeling to address voting collision and iterative noise filtering. We introduce N-point tuples for richer voting context and a new dataset, DiversePose 300, to test current methods in diverse scenarios. Our results show CPPF++ significantly reduces the gap between simulation and real-world performance. |
 | PACE: Pose Annotations in Cluttered EnvironmentsYang You, Kai Xiong, Zhening Yang, Zhengxiang Huang, Junwei Zhou, Ruoxi Shi, Zhou Fang, Adam W Harley, Cewu LuECCV, 2024 arxiv / supplementary / code / Project Page /Pose estimation is vital for tracking and manipulating objects in images or videos. Existing datasets lack a focus on cluttered scenes with occlusions, hindering real-world application development. To address this, we introduce PACE (Pose Annotations in Cluttered Environments), a large-scale benchmark for evaluating pose estimation methods in cluttered scenarios. PACE includes 54,945 frames with 257,673 annotations across 300 videos, featuring 576 objects from 44 categories. An innovative annotation system with a 3-camera setup was developed for efficient real-world data annotation. |
 | RPMArt: Towards Robust Perception and Manipulation for Articulated ObjectsJunbo Wang, Wenhai Liu, Qiaojun Yu, Yang You, Liu Liu, Weiming Wang, and Cewu LuIROS, 2024 arxiv / code / Project Page /Articulated objects are common in daily life, requiring robots to have robust perception and manipulation skills. Current methods struggle with noise in point clouds and bridging the gap between simulation and reality. We propose RPMArt, a framework for robust perception and manipulation of articulated objects, learning to estimate articulation parameters from noisy point clouds. Our main contribution, RoArtNet, predicts joint parameters and affordable points using local feature learning and point tuple voting. An articulation-aware classification scheme enhances sim-to-real transfer. RPMArt achieves state-of-the-art performance in both noise-added simulations and real-world environments. |
 | SparseDFF: Sparse-View Feature Distillation for One-Shot Dexterous ManipulationQianxu Wang, Haotong Zhang, Congyue Deng, Yang You, Hao Dong, Yixin Zhu, Leonidas GuibasICLR, 2024 arxiv / Project Page /Humans excel at transferring manipulation skills across diverse objects due to their understanding of semantic correspondences. To give robots similar abilities, we develop a method for acquiring view-consistent 3D Distilled Feature Fields (DFF) from sparse RGBD observations. Our approach, \method, maps image features to 3D point clouds, creating a dense feature field for one-shot learning of dexterous manipulations transferable to new scenes. The core of \method is a lightweight feature refinement network, optimized with contrastive loss between pairwise views. We also use point-pruning to enhance feature continuity. Evaluations show our method enables robust manipulations of rigid and deformable objects, demonstrating strong generalization to varying objects and scene contexts. |
 | Make a Donut: Language-Guided Hierarchical EMD-Space Planning for Zero-shot Deformable Object ManipulationYang You, Bokui Shen, Congyue Deng, Haoran Geng, He Wang, Leonidas GuibasRA-L,IROS, 2025 arxiv / code / poster / Project Page /Deformable object manipulation is a challenging area in robotics, often relying on demonstrations to learn task dynamics. However, obtaining suitable demonstrations for long-horizon tasks is difficult and can limit model generalization. We propose a demonstration-free hierarchical planning approach for complex long-horizon tasks without training. Using large language models (LLMs), we create a high-level, stage-by-stage plan for a task, specifying tools and generating Python code for intermediate subgoal point clouds. With these, we employ a closed-loop model predictive control strategy using Differentiable Physics with Point-to-Point correspondence (DiffPhysics-P2P) loss in the earth mover distance (EMD) space. Our method outperforms benchmarks in dough manipulation tasks and generalizes well to novel tasks without demonstrations, validated through real-world robotic experiments. |
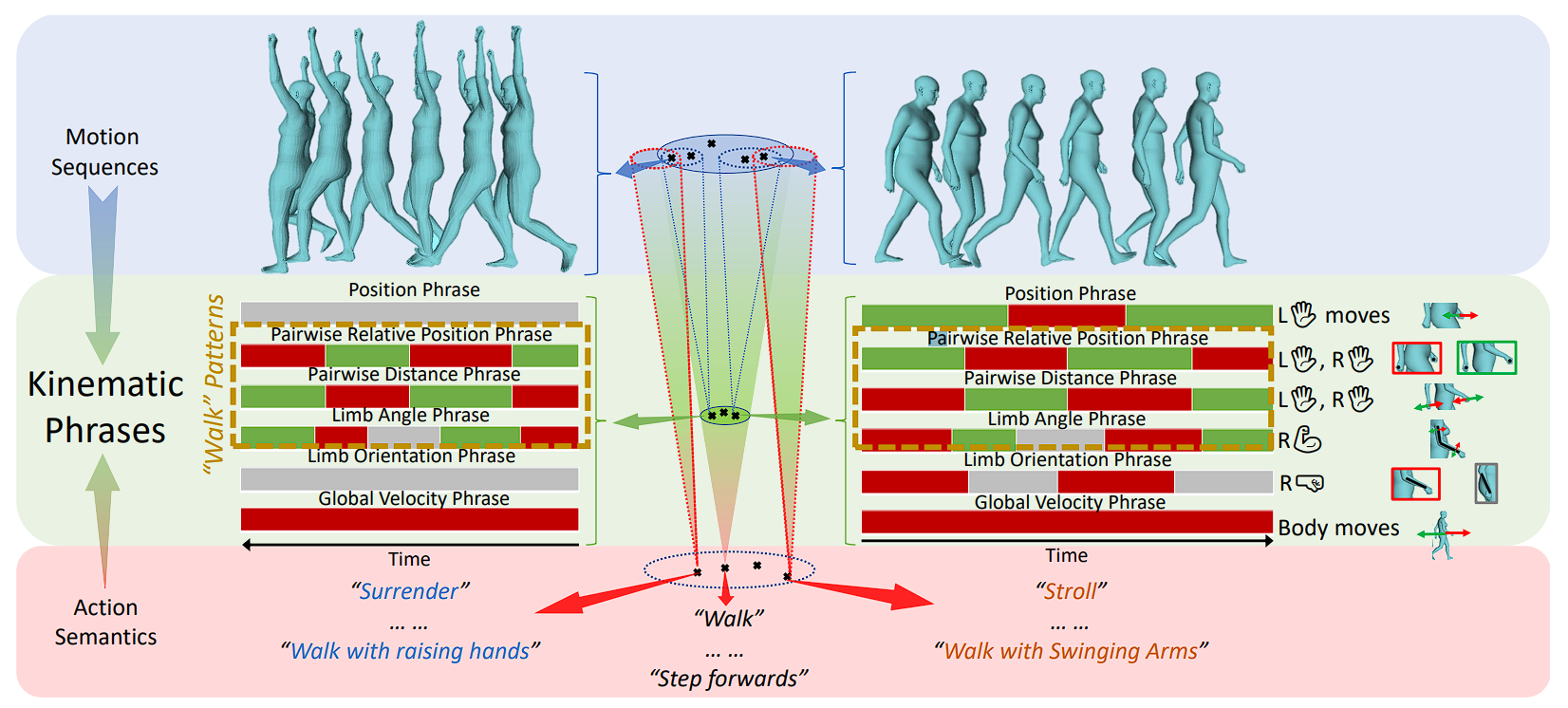 | Bridging the Gap between Human Motion and Action Semantics via Kinematic PhrasesXinpeng Liu, Yong-Lu Li, Ailing Zeng, Zizheng Zhou, Yang You, Cewu LuECCV, 2024 arxiv / Project Page /Motion understanding aims to map motion to action semantics, but the variability in both makes this challenging. Abstract actions like 'walk forwards' can be conveyed by diverse motions, while a single motion can have different meanings depending on context. Previous direct-mapping methods are unreliable, and current metrics fail to consistently assess motion-semantics alignment. To bridge this gap, we propose Kinematic Phrases (KP), which abstractly and objectively represent human motion with interpretability and generality. Using KP, we unify a motion knowledge base and build a motion understanding system. KP also enables Kinematic Prompt Generation (KPG), a novel benchmark for automatic motion generation. Experiments show our approach outperforms others, and we plan to release our code and data publicly. |
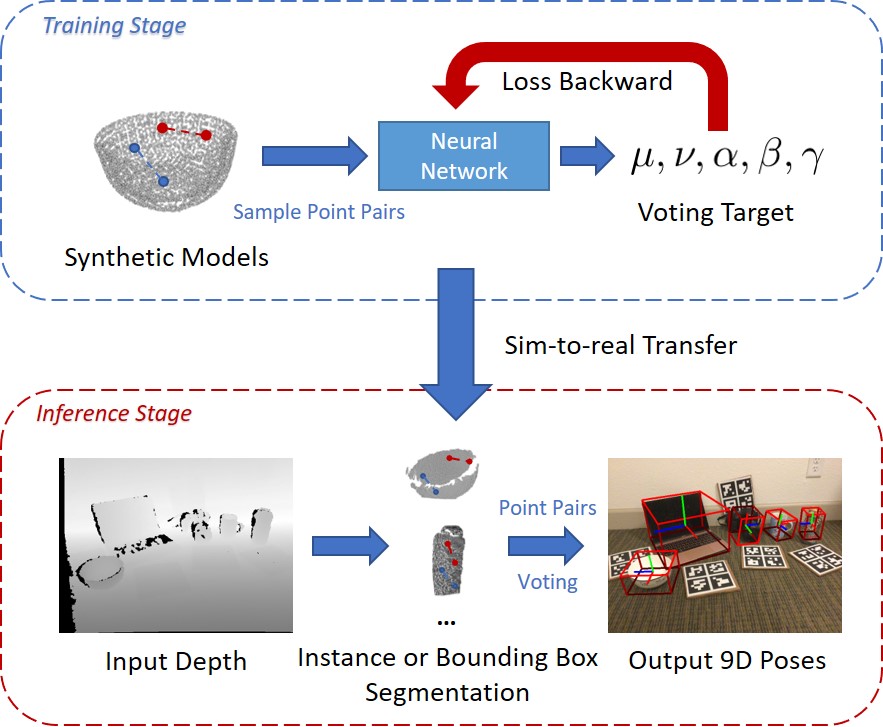 | CPPF: Towards Robust Category-Level 9D Pose Estimation in the WildYang You, Ruoxi Shi, Weiming Wang, Cewu LuCVPR, 2022 arxiv / code / Project Page /This paper addresses category-level 9D pose estimation in the wild using a single RGB-D frame. Inspired by traditional point pair features (PPFs), we introduce a novel Category-level PPF (CPPF) voting method for accurate, robust, and generalizable 9D pose estimation. Our approach samples numerous point pairs on an object, predicting SE(3)-invariant voting statistics for object centers, orientations, and scales. We propose a coarse-to-fine voting algorithm to filter out noisy samples and refine predictions. An auxiliary binary classification task helps eliminate false positives in orientation voting. To ensure robustness, our sim-to-real pipeline trains on synthetic point clouds, except for geometrically ambiguous objects. |
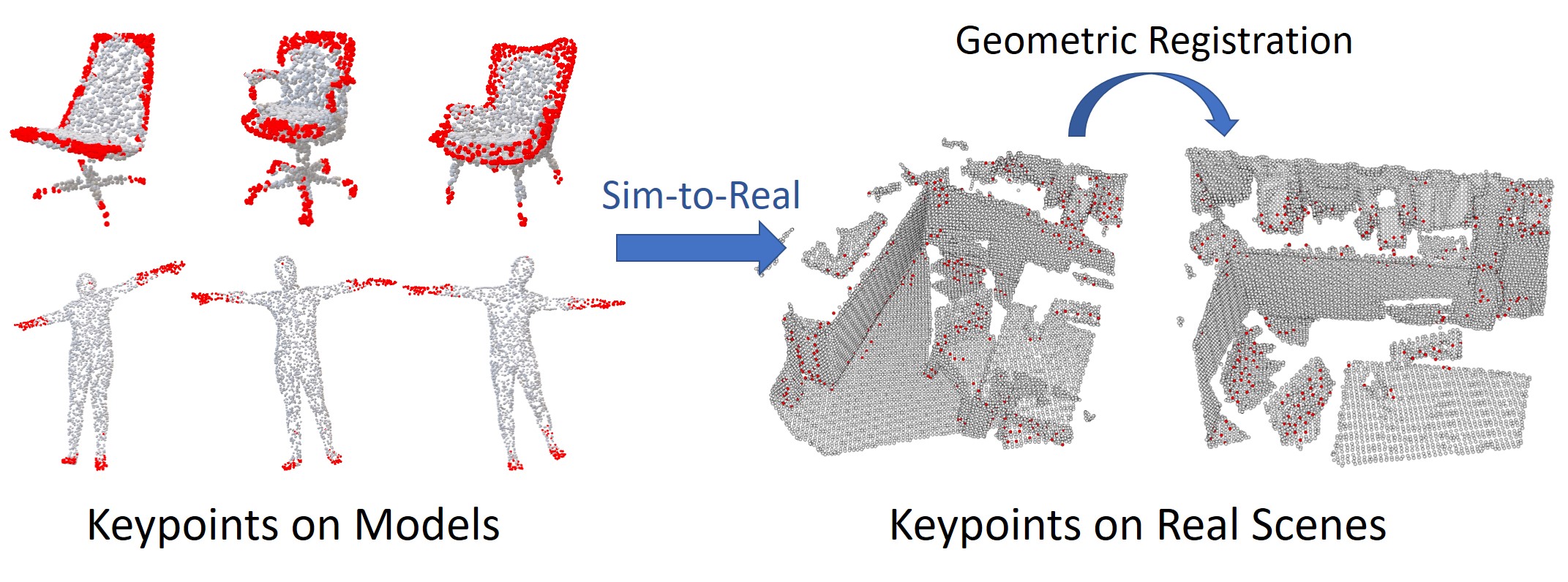 | UKPGAN: Unsupervised KeyPoint GANerationYang You, Wenhai Liu, Yong-Lu Li, Weiming Wang, Cewu LuCVPR, 2022 arxiv / code / Project Page /In this work, we reckon keypoints under an information compression scheme to represent the whole object. Based on this, we propose UKPGAN, an unsupervised 3D keypoint detector where keypoints are detected so that they could reconstruct the original object shape. Two modules: GAN-based keypoint sparsity control and salient information distillation modules are proposed to locate those important keypoints. Extensive experiments show that our keypoints preserve the semantic information of objects and align well with human annotated part and keypoint labels. |
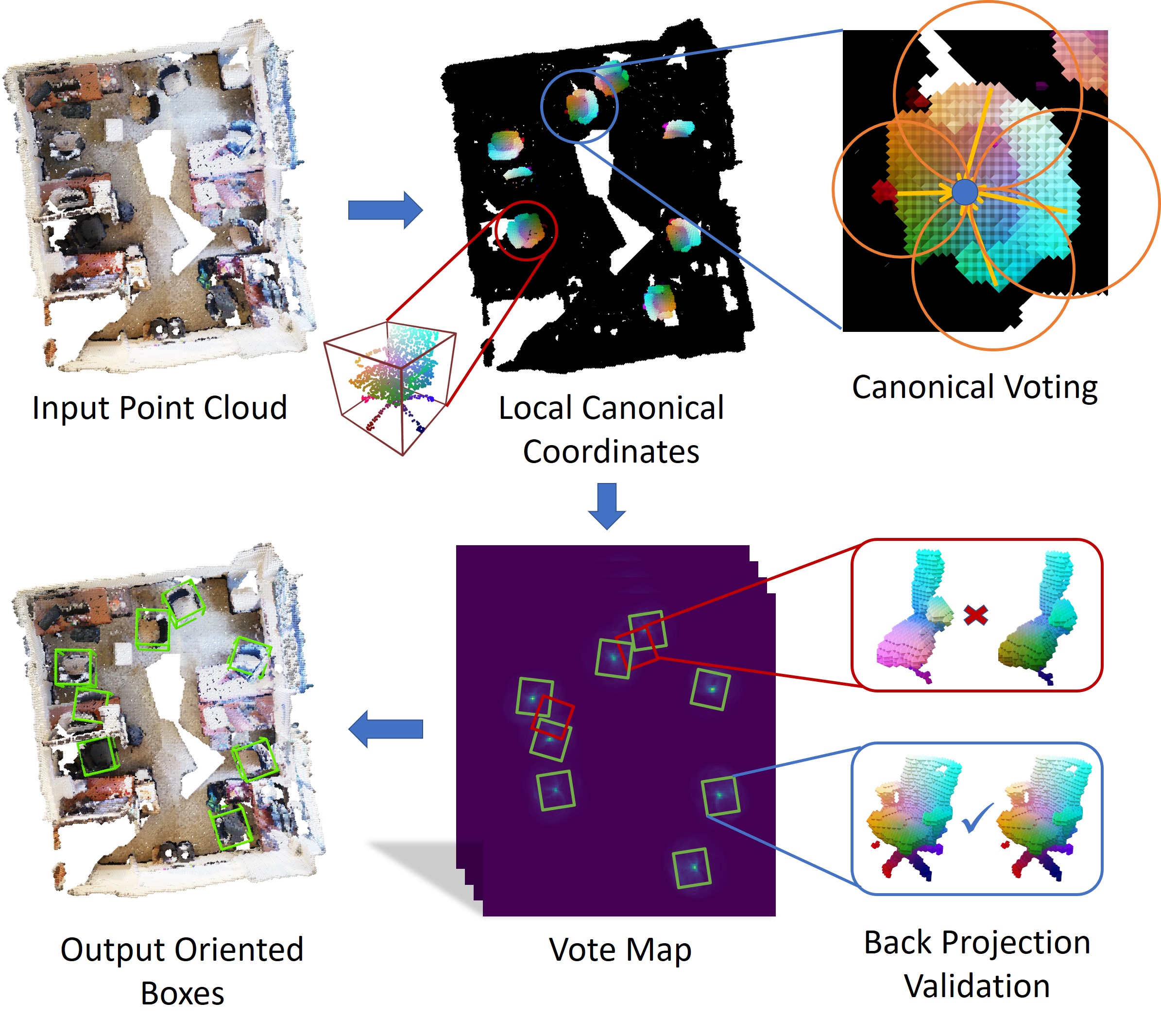 | Canonical Voting: Towards Robust Oriented Bounding Box Detection in 3D ScenesYang You, Zelin Ye, Yujing Lou, Chengkun Li, Yong-Lu Li, Lizhuang Ma, Weiming Wang, Cewu LuCVPR, 2022 arxiv / code / Project Page /In the work, we disentangle the direct offset into Local Canonical Coordinates (LCC), box scales and box orientations. Only LCC and box scales are regressed while box orientations are generated by a canonical voting scheme. Finally, a LCC-aware back-projection checking algorithm iteratively cuts out bounding boxes from the generated vote maps, with the elimination of false positives. Our model achieves state-of-the-art performance on challenging large-scale datasets of real point cloud scans: ScanNet, SceneNN with 11.4 and 5.3 mAP improvement respectively. |
 | PRIN/SPRIN: On Extracting Point-wise Rotation Invariant FeaturesYang You, Yujing Lou, Ruoxi Shi, Qi Liu, Yu-Wing Tai, Lizhuang Ma, Weiming Wang, Cewu LuTPAMI, 2021 arxiv / code /Point cloud analysis without pose priors is very challenging in real applications, as the orientations of point clouds are often unknown. In this paper, we propose a brand new point-set learning framework PRIN, namely, Point-wise Rotation Invariant Network, focusing on rotation invariant feature extraction in point clouds analysis. We construct spherical signals by Density Aware Adaptive Sampling to deal with distorted point distributions in spherical space. Spherical Voxel Convolution and Point Re-sampling are proposed to extract rotation invariant features for each point. In addition, we extend PRIN to a sparse version called SPRIN, which directly operates on sparse point clouds. Both PRIN and SPRIN can be applied to tasks ranging from object classification, part segmentation, to 3D feature matching and label alignment. Results show that, on the dataset with randomly rotated point clouds, SPRIN demonstrates better performance than state-of-the-art methods without any data augmentation. We also provide thorough theoretical proof and analysis for point-wise rotation invariance achieved by our methods. |
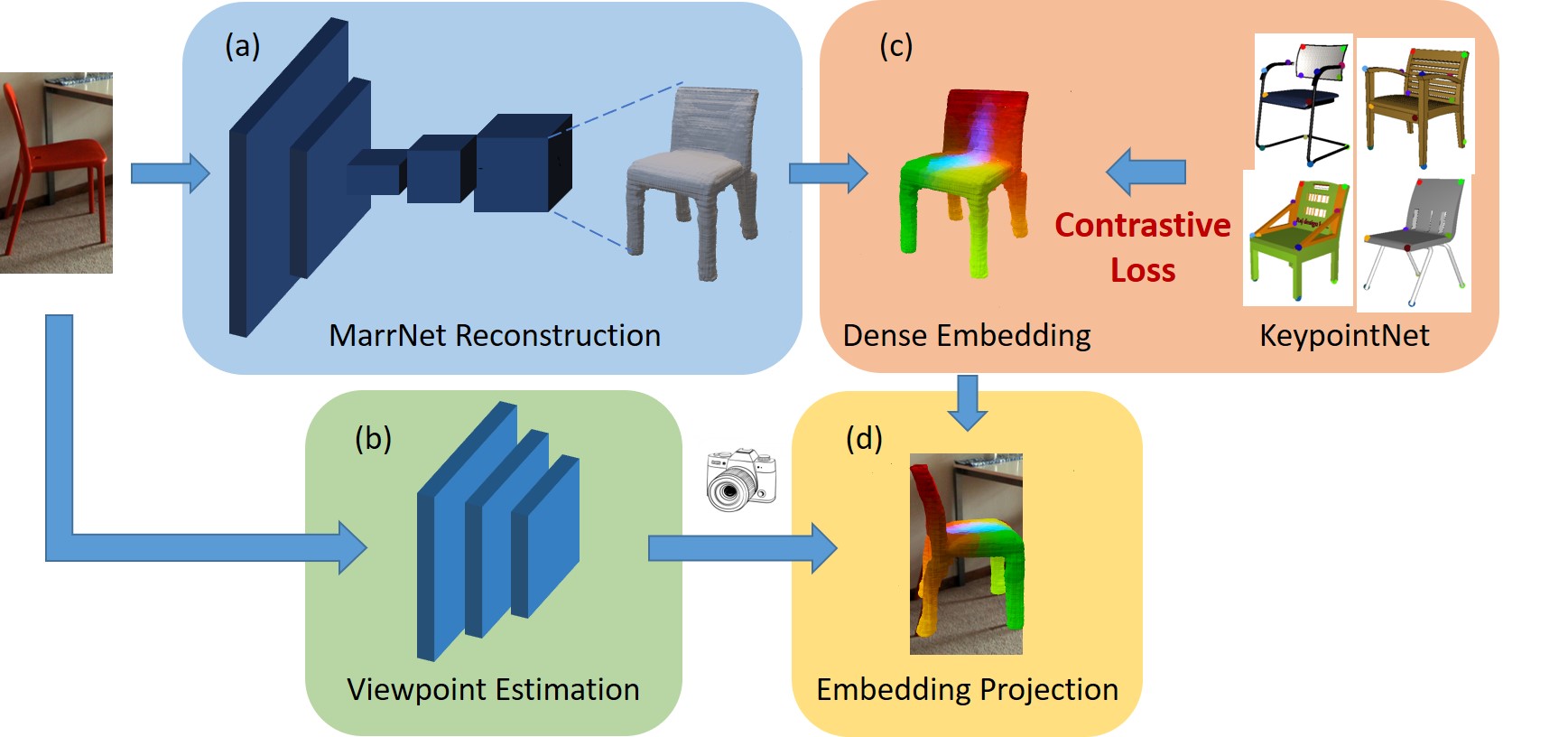 | Understanding Pixel-level 2D Image Semantics with 3D Keypoint Knowledge EngineYang You, Chengkun Li, Yujing Lou, Zhoujun Cheng, Liangwei Li, Lizhuang Ma, Weiming Wang, Cewu LuTPAMI, 2021 arxiv /Pixel-level 2D object semantic understanding is an important topic in computer vision and could help machine deeply understand objects (e.g. functionality and affordance) in our daily life. However, most previous methods directly train on correspondences in 2D images, which is end-to-end but loses plenty of information in 3D spaces. In this paper, we propose a new method on predicting image corresponding semantics in 3D domain and then projecting them back onto 2D images to achieve pixel-level understanding. In order to obtain reliable 3D semantic labels that are absent in current image datasets, we build a large scale keypoint knowledge engine called KeypointNet, which contains 103,450 keypoints and 8,234 3D models from 16 object categories. Our method leverages the advantages in 3D vision and can explicitly reason about objects self-occlusion and visibility. We show that our method gives comparative and even superior results on standard semantic benchmarks. |
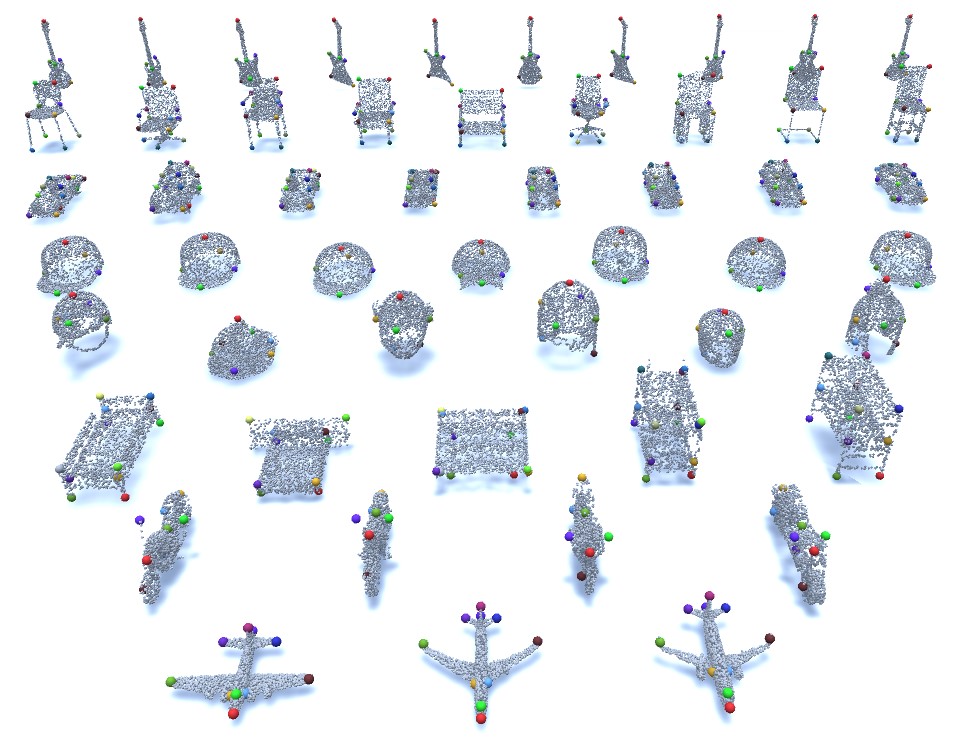 | KeypointNet: A Large-scale 3D Keypoint Dataset Aggregated from Numerous Human AnnotationsYang You, Yujing Lou, Chengkun Li, Zhoujun Cheng, Liangwei Li, Lizhuang Ma, Cewu Lu, Weiming WangCVPR, 2020 arxiv / video / code / Project Page /We present KeypointNet: the first large-scale and diverse 3D keypoint dataset that contains 83,231 keypoints and 8,329 3D models from 16 object categories, by leveraging numerous human annotations. To handle the inconsistency between annotations from different people, we propose a novel method to aggregate these keypoints automatically, through minimization of a fidelity loss. Finally, ten state-of-the-art methods are benchmarked on our proposed dataset. |
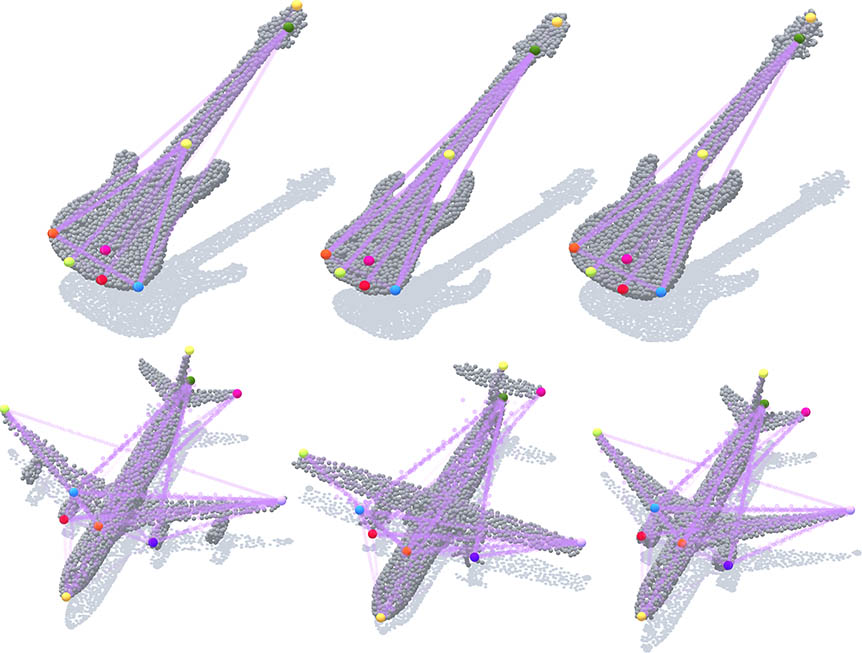 | Skeleton Merger, an Unsupervised Aligned Keypoint DetectorRuoxi Shi, Zhengrong Xue, Yang You, Cewu LuCVPR, 2021 arxiv / code /In this paper, we propose an unsupervised aligned keypoint detector, Skeleton Merger, which utilizes skeletons to reconstruct objects. It is based on an Autoencoder architecture. The encoder proposes keypoints and predicts activation strengths of edges between keypoints. The decoder performs uniform sampling on the skeleton and refines it into small point clouds with pointwise offsets. Then the activation strengths are applied and the sub-clouds are merged. Composite Chamfer Distance (CCD) is proposed as a distance between the input point cloud and the reconstruction composed of sub-clouds masked by activation strengths. |
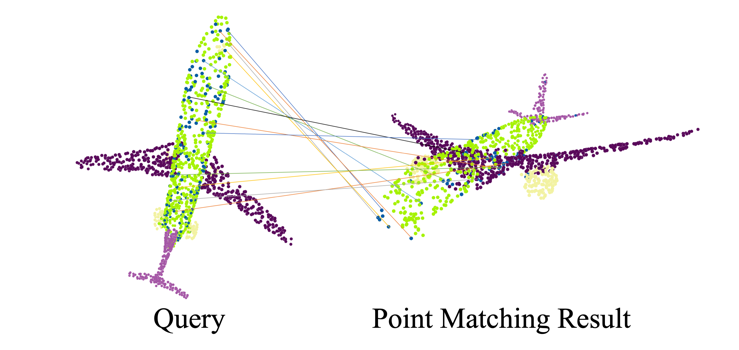 | Pointwise Rotation-Invariant Network with Adaptive Sampling and 3D Spherical Voxel ConvolutionYang You, Yujing Lou, Qi Liu, Yu-Wing Tai, Lizhuang Ma, Cewu Lu, Weiming WangAAAI, 2020 arxiv / code /In this paper, we propose a new point-set learning framework named Pointwise Rotation-Invariant Network (PRIN), focusing on achieving rotation-invariance in point clouds. We construct spherical signals by Density-Aware Adaptive Sampling (DAAS) from sparse points and employ Spherical Voxel Convolution (SVC) to extract rotation-invariant features for each point. Our network can be applied to applications ranging from object classification, part segmentation, to 3D feature matching and label alignment. |
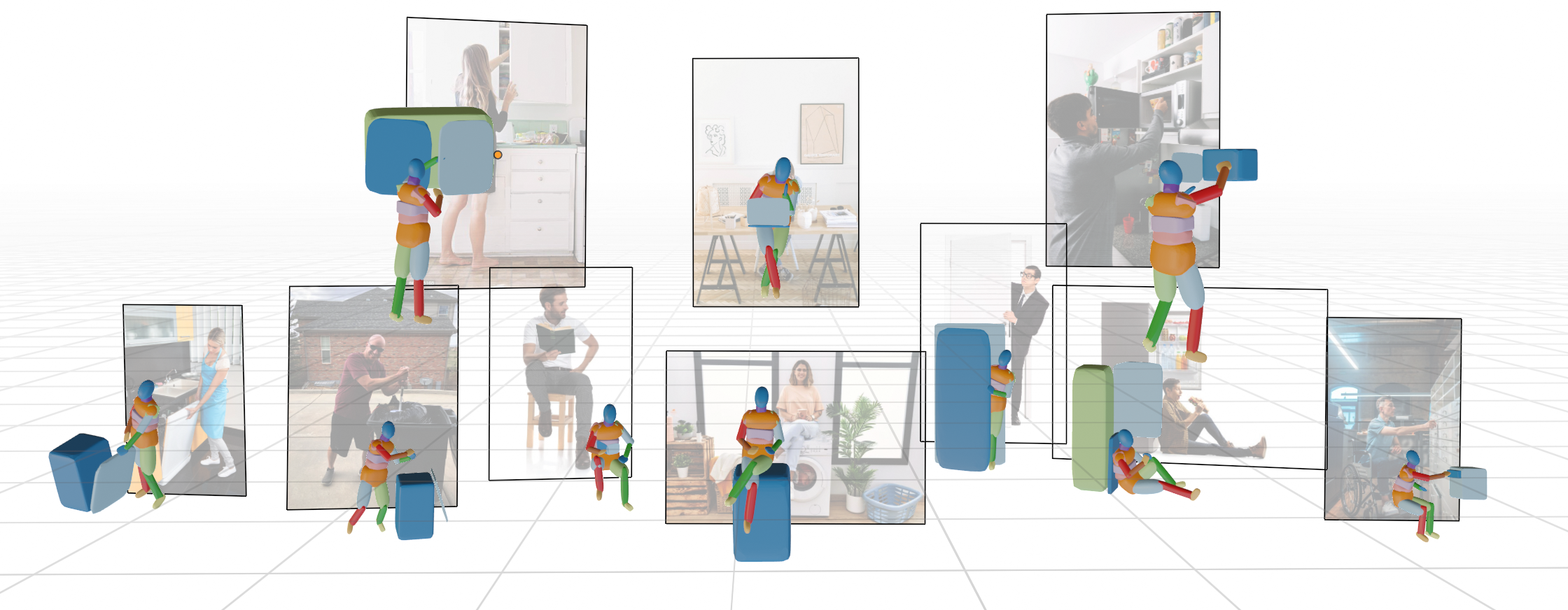 | Primitive-based 3D Human-Object Interaction Modelling and ProgrammingSiqi Liu, Yong-Lu Li, Zhou Fang, Xinpeng Liu, Yang You, Cewu LuAAAI, 2024 arxiv / Project Page /Embedding Human and Articulated Object Interaction (HAOI) in 3D is crucial for understanding human activities. Unlike previous works using parametric and CAD models, we propose a novel approach using 3D geometric primitives to encode both humans and objects. In our paradigm, humans and objects are compositions of primitives, enabling mutual information learning between limited 3D human data and various object categories. We choose superquadrics as our primitive representation for their simplicity and rich information. We introduce a new 3D HAOI benchmark with primitives and their images and propose a task for machines to recover 3D HAOI from images. Additionally, we provide a baseline for single-view 3D reconstruction on HAOI, paving the way for future 3D HAOI research. |
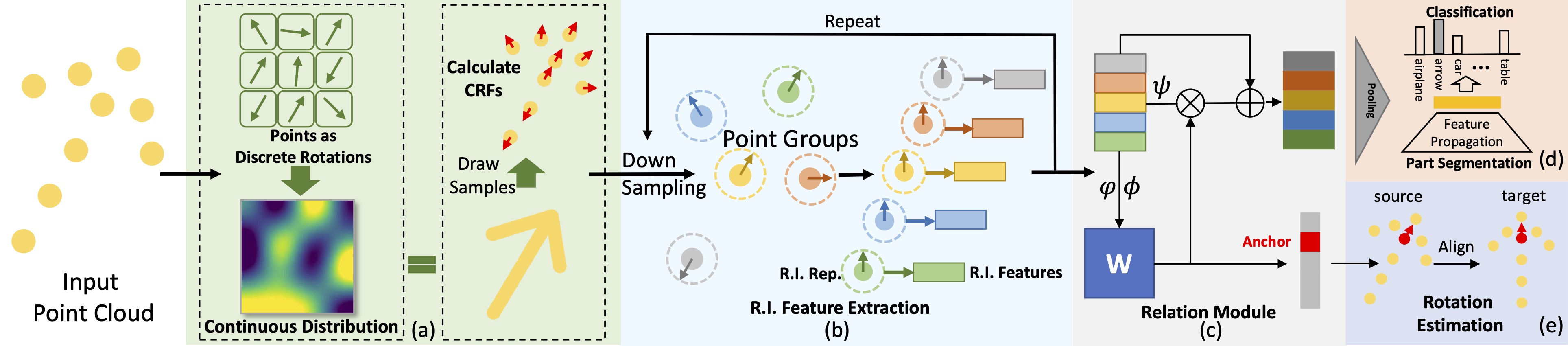 | CRIN: Rotation-Invariant Point Cloud Analysis and Rotation Estimation via Centrifugal Reference FrameYujing Lou, Zelin Ye, Yang You, Nianjuan Jiang, Jiangbo Lu, Weiming Wang, Lizhuang Ma, Cewu LuAAAI, 2023 arxiv / code /In this paper, we propose the CRIN, namely Centrifugal Rotation-Invariant Network. CRIN directly takes the coordinates of points as input and transforms local points into rotation-invariant representations via centrifugal reference frames. Aided by centrifugal reference frames, each point corresponds to a discrete rotation so that the information of rotations can be implicitly stored in point features. Unfortunately, discrete points are far from describing the whole rotation space. We further introduce a continuous distribution for 3D rotations based on points. Furthermore, we propose an attention-based down-sampling strategy to sample points invariant to rotations. A relation module is adopted at last for reinforcing the long-range dependencies between sampled points and predicts the anchor point for unsupervised rotation estimation. Extensive experiments show that our method achieves rotation invariance, accurately estimates the object rotation. Ablation studies validate the effectiveness of the network design. |
 | Relative CNN-RNN: Learning relative atmospheric visibility from imagesYang You, Cewu Lu, Weiming Wang, Chi-Keung TangIEEE Transactions on Image Processing, 2018 PDF /We propose a deep learning approach for directly estimating relative atmospheric visibility from outdoor photos without relying on weather images or data that require expensive sensing or custom capture. Our data-driven approach capitalizes on a large collection of Internet images to learn rich scene and visibility varieties. The relative CNN-RNN coarse-to-fine model, where CNN stands for convolutional neural network and RNN stands for recurrent neural network, exploits the joint power of relative support vector machine, which has a good ranking representation, and the data-driven deep learning features derived from our novel CNN-RNN model. |
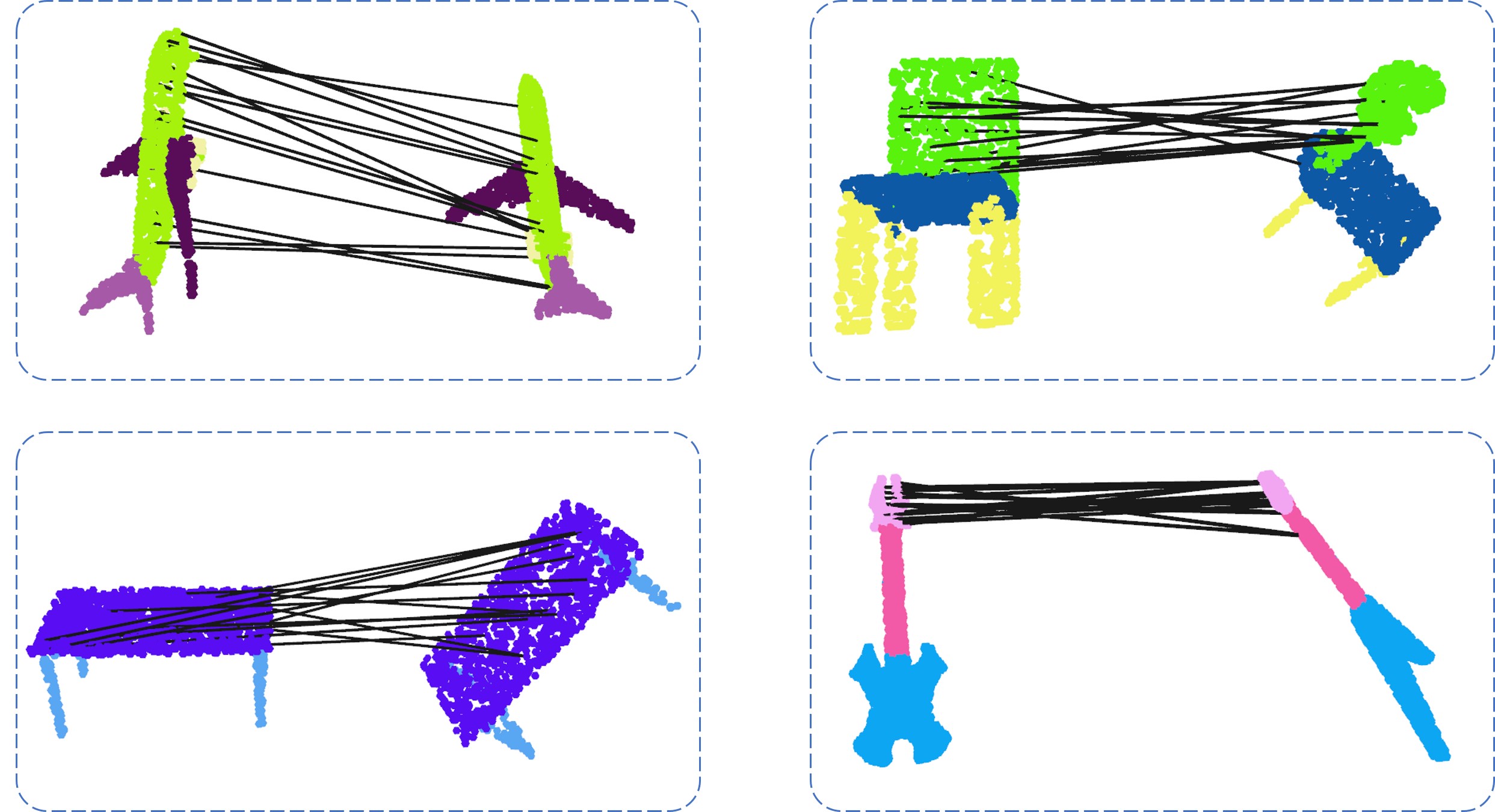
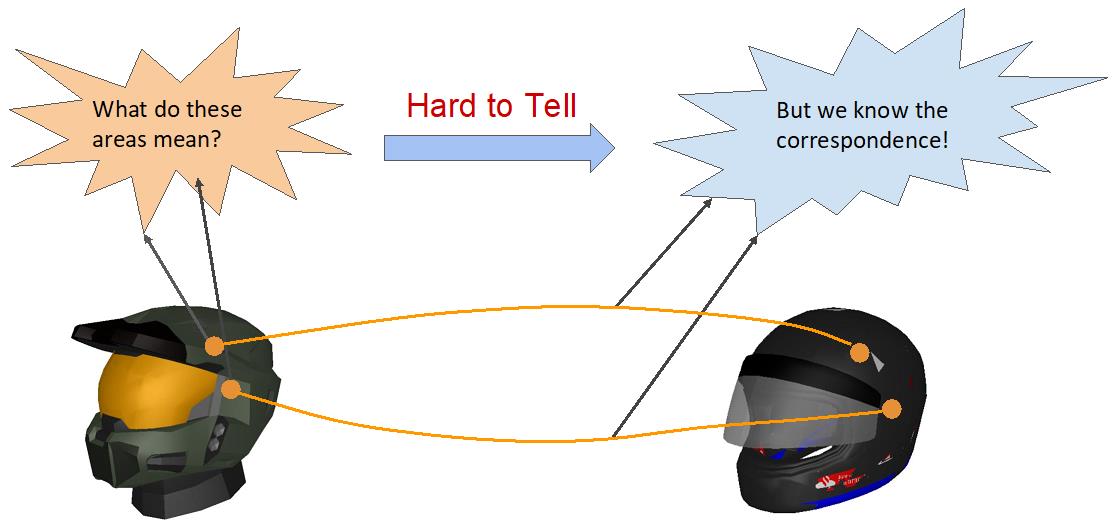 | Human Correspondence Consensus for 3D Object Semantic UnderstandingYujing Lou*, Yang You*, Chengkun Li*, Zhoujun Cheng, Liangwei Li, Lizhuang Ma, Weiming Wang, Yuwing Tai, Cewu Lu (*=equal contribution)ECCV, 2020 arxiv /We observe that people have a consensus on semantic correspondences between two areas from different objects, but are less certain about the exact semantic meaning of each area. Therefore, we argue that by providing human labeled correspondences between different objects from the same category instead of explicit semantic labels, one can recover rich semantic information of an object. In this paper, we introduce a new dataset named CorresPondenceNet. Based on this dataset, we are able to learn dense semantic embeddings with a novel geodesic consistency loss. |
 | Combinational Q-Learning for Dou Di ZhuYang You, Liangwei Li, Baisong Guo, Weiming Wang, Cewu LuAIIDE, 2020 arxiv / code /In this paper, we study a special class of Asian popular card games called Dou Di Zhu, in which two adversarial groups of agents must consider numerous card combinations at each time step, leading to huge number of actions. We propose a novel method to handle combinatorial actions, which we call combinational Q-learning (CQL). We employ a two-stage network to reduce action space and also leverage order-invariant max-pooling operations to extract relationships between primitive actions. |
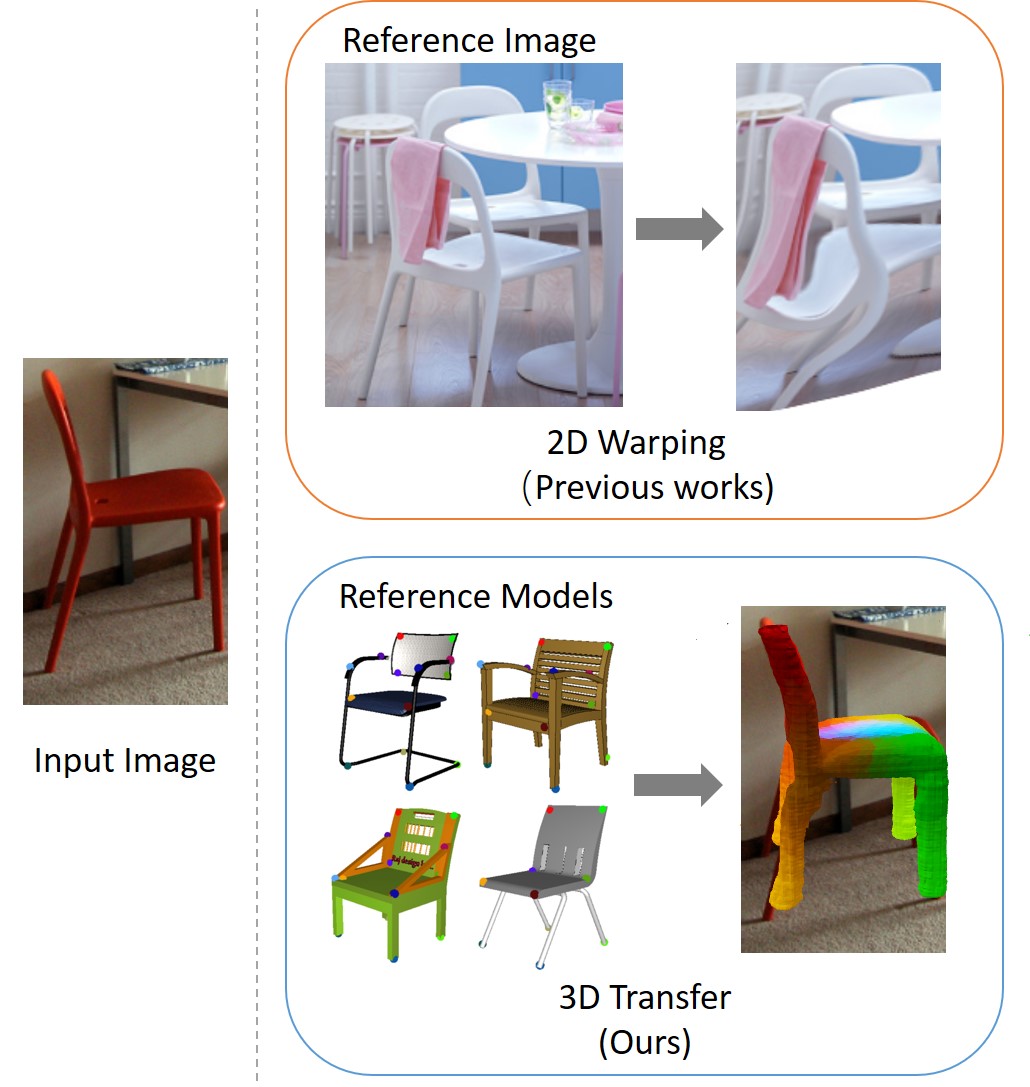 | Semantic Correspondence via 2D-3D-2D CycleYang You, Chengkun Li, Yujing Lou, Zhoujun Cheng, Lizhuang Ma, Cewu Lu, Weiming WangPreprint, 2020 arxiv / code /Visual semantic correspondence is an important topic in computer vision and could help machine understand objects in our daily life. However, most previous methods directly train on correspondences in 2D images, which is end-to-end but loses plenty of information in 3D spaces. In this paper, we propose a new method on predicting semantic correspondences by leveraging it to 3D domain and then project corresponding 3D models back to 2D domain, with their semantic labels. Our method leverages the advantages in 3D vision and can explicitly reason about objects self-occlusion and visibility. |